1. HAMi是什么
想象一下你是一位繁忙的AI研究员,手头有好几个实验要跑,但实验室里的GPU显卡资源有限。这时候,HAMi就像一位智慧的资源管理员,帮你合理分配和调度这些宝贵的GPU资源。它就像是给GPU装上了"分身术",让多个AI任务能够和谐共处在同一块显卡上。HAMi目前已经加入了云原生界的"黄埔军校"CNCF(云原生计算基金会),作为一个充满潜力的沙箱项目茁壮成长。
让我们通过几个生动的场景,来了解HAMi的神奇之处:
-
设备共享有妙招,就像一个灵活的"设备调度大师":
- 不管是GPU还是NPU,都能轻松管理,就像训练有素的管家
- 一个AI任务想要多个显卡?没问题!就像给你配备多位得力助手
-
显存管理很智能,犹如一位精明的"内存管家":
- 每个任务的显存使用都有明确的"配额",不会互相争抢
- 需要更多显存?可以随时调整,就像弹性伸缩的口袋
- 想用具体数值还是百分比来分配?都可以,就像点菜可以按份量也可以按比例
-
设备挑选很贴心,像个专业的"设备配对专家":
- 只想用RTX 4090?没问题,就像指定特定型号的跑车
- 还能通过UUID精确定位设备,就像每个显卡都有自己的身份证
-
上手特别容易,就像一个"零门槛"的好帮手:
- AI程序完全不用改代码,就像无缝衔接的魔法
- 安装卸载像玩积木一样简单,helm工具轻松搞定
-
开放合作大家庭,像一个温暖的"开源社区":
- 各行各业的大咖都在参与,从互联网到金融,从制造业到云服务
- 加入CNCF大家庭,让更多朋友一起来建设,就像一个开放的创新工坊
2. HAMi架构
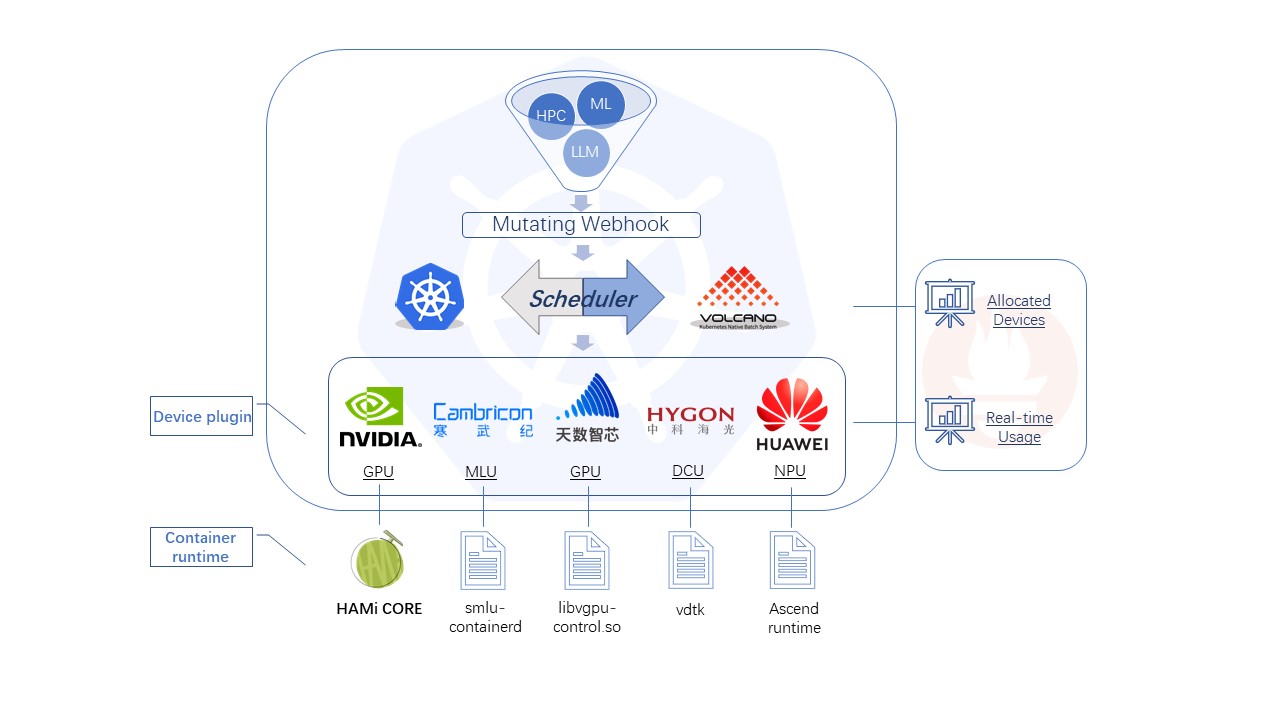
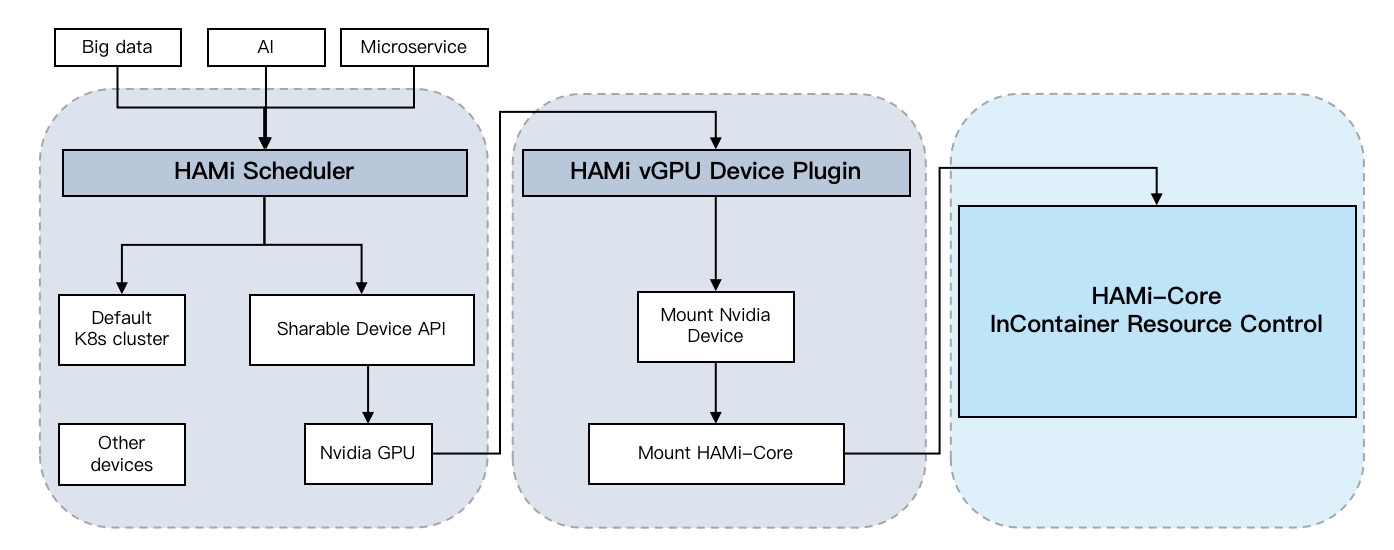 HAMi这套架构就像一个高效运转的智能办公大楼,由四个关键人员协同工作:
HAMi这套架构就像一个高效运转的智能办公大楼,由四个关键人员协同工作:
-
前台接待员(HAMi MutatingWebhook)就像大楼的智能前台,当新的AI任务来访时:
- 会仔细检查访客的"需求清单"(资源申请)
- 如果发现这位访客只需要基础设施(CPU、内存)或HAMi特供服务,就会贴上"HAMi特别通行证"
- 相当于一位细心的门卫,确保每个来访者都能得到合适的接待方式
-
调度主管(HAMi scheduler-extender)犹如大楼的总调度室管理员:
- 负责给每位访客安排最合适的办公位置(节点)和工作设备(GPU/NPU)
- 就像有一个实时更新的"全楼设备状态大屏",随时掌握每个设备的使用情况
- 能够根据访客需求和设备状态,做出最优的分配决策
-
设备管家(Device-plugin)像是一位神通广大的设备连接专家:
- 看到调度主管的工位安排单后,立即着手准备相应的设备
- 负责将显卡等设备"插上电源",确保设备随时可用
- 就像是在访客和设备之间搭建一座便捷的桥梁
-
资源管控员(HAMi-Core)就像一位尽职的资源监管员:
- 时刻关注每个访客的资源使用情况,确保不会超出预定配额
- 设置明确的资源使用界限,防止互相干扰
- 当某个任务试图占用过多资源时,会及时进行管控
3. HAMi应用场景
3.1 设备共享
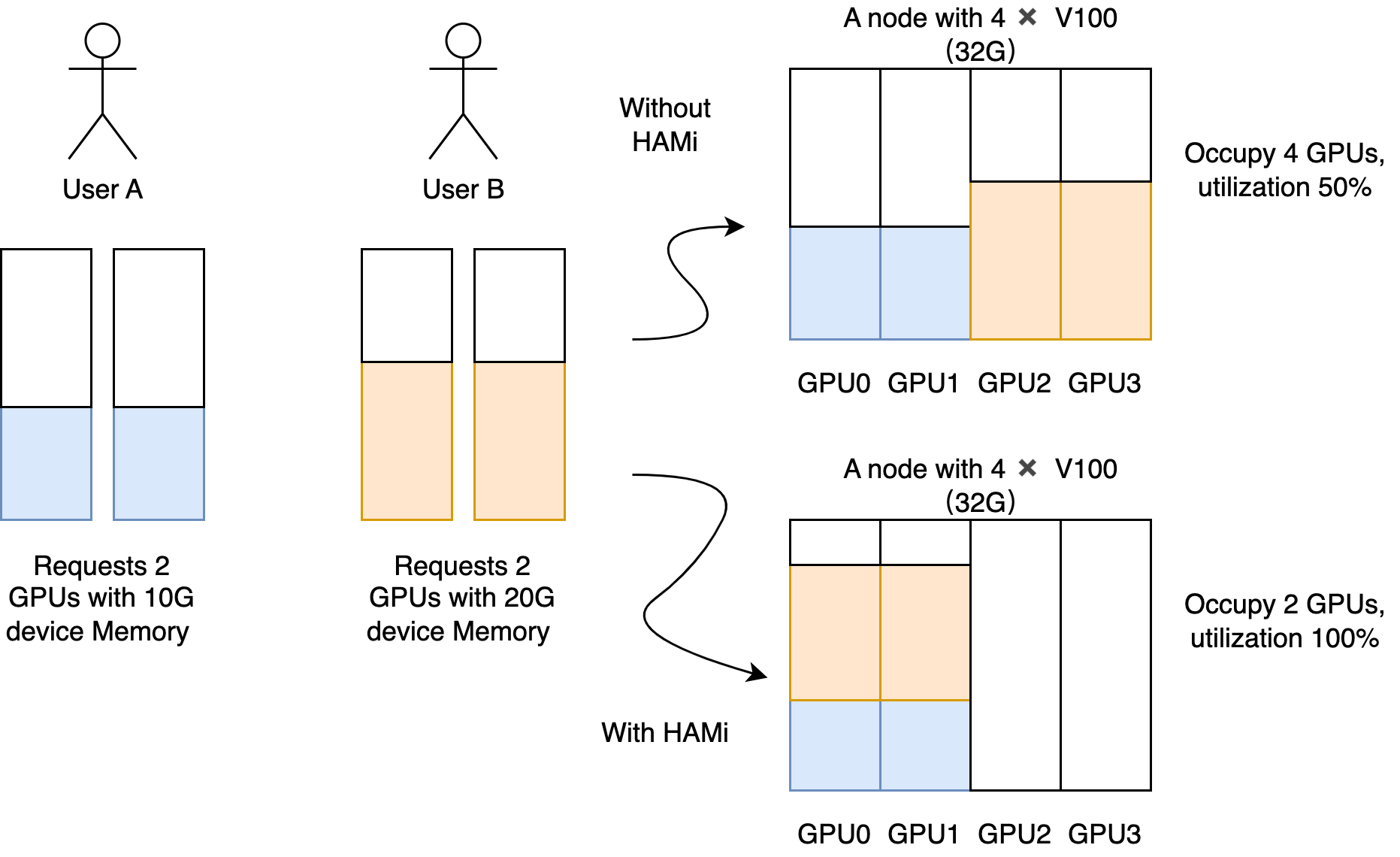
HAMi的设备共享就像是一个智能的资源分配系统,让一块显卡能够同时服务多个AI任务:
-
灵活的显存分配
- 可以精确指定每个任务使用多少显存
- 就像给每个租户分配固定大小的"储物柜"
-
算力精确控制
- 对计算单元(流处理器)进行严格限制
- 就像给每个租户分配固定数量的"工作人员"
-
核心使用率管理
- 支持按需分配设备核心使用率
- 就像给不同任务分配不同的"工作时间"
-
无缝适配已有程序
- 完全不需要修改现有的程序代码
- 就像租客入住时不需要重新装修,直接拎包入住
3.2 设备资源隔离
resources:
limits:
nvidia.com/gpu: 1 # 请求1个虚拟GPU
nvidia.com/gpumem: 3000 # 每个虚拟GPU包含3000MB设备内存
在容器内部看到的1张卡,显存3GB
4. Helm部署HAMi
4.1 前置条件
- Helm version v3+
- kubectl version v1.16+
- CUDA version v10.2+
- Nvidia Driver version v440+
4.2 配置nvidia runtime
安装nvidia-container-toolkit,配置nvidia-container-runtime
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/libnvidia-container.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
# 如果container runtime使用的是docker
vim /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
sudo systemctl daemon-reload && systemctl restart docker
# 如果container runtime使用的是containerd
(base) root@vgpu:/root# nvidia-ctk runtime configure --runtime=containerd
INFO[0000] Wrote updated config to /etc/containerd/config.toml
INFO[0000] It is recommended that containerd daemon be restarted.
# 如果container runtime使用的是containerd
vim /etc/containerd/config.toml
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
sudo systemctl daemon-reload && systemctl restart containerd
为containerd配置代理(docker daemon同理)
vim /etc/systemd/system/containerd.service
[Service]
Environment="HTTP_PROXY=http://<代理地址>:<代理端口>"
Environment="HTTPS_PROXY=http://<代理地址>:<代理端口>"
Environment="NO_PROXY=localhost,127.0.0.1"
4.3 GPU节点标签
kubectl label nodes {nodeid} gpu=on
4.4 部署HAMi
image_version=$(kubectl version 2>/dev/null | grep GitVersion | head -1 | awk -F'"' '{print $6}')
helm repo add hami-charts https://project-hami.github.io/HAMi/
helm install hami hami-charts/hami --set scheduler.kubeScheduler.imageTag=${image_version} -n kube-system
4.5 验证HAMi
创建gpu pod
# 创建一个测试用的Pod,用于验证HAMi的基本功能
cat << 'EOF' | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 vGPUs
nvidia.com/gpumem: 10240 # Each vGPU contains 3000m device memory (Optional,Integer)
EOF
进入到容器里查看,可以看到1张卡,显存1GB
(base) root@vgpu:~# kubectl exec -it gpu-pod -- nvidia-smi
[HAMI-core Msg(24:139957573396288:libvgpu.c:836)]: Initializing.....
Fri Dec 13 05:55:05 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.135 Driver Version: 550.135 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:00:05.0 Off | N/A |
| 0% 26C P8 7W / 370W | 0MiB / 10240MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
[HAMI-core Msg(24:139957573396288:multiprocess_memory_limit.c:497)]: Calling exit handler 24
4.6 多pod共享GPU
# 创建一个包含3个Pod的Deployment,用于测试GPU共享功能
cat << 'EOF' | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: hami-npod-1gpu
spec:
replicas: 3 # 创建三个相同的 Pod,可根据需要修改数量
selector:
matchLabels:
app: pytorch
template:
metadata:
labels:
app: pytorch
spec:
containers:
- name: pytorch-container
image: uhub.service.ucloud.cn/gpu-share/gpu_pytorch_test:latest
command: ["/bin/sh", "-c"]
args: ["cd /app/pytorch_code && python3 2.py"]
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 3000
nvidia.com/gpucores: 25
EOF
# 查看创建的Pod状态
(base) root@vgpu:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
hami-npod-1gpu-6f65f668b7-6k2jh 1/1 Running 0 5s
hami-npod-1gpu-6f65f668b7-f48gm 1/1 Running 0 5s
hami-npod-1gpu-6f65f668b7-kpnbg 1/1 Running 0 5s
# 查看主机上的GPU使用情况
(base) root@vgpu:~# nvidia-smi
Fri Dec 13 09:32:47 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.135 Driver Version: 550.135 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:00:05.0 Off | N/A |
| 34% 33C P2 103W / 370W | 1320MiB / 24576MiB | 2% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 19635 C python3 478MiB |
| 0 N/A N/A 19713 C python3 478MiB |
| 0 N/A N/A 19900 C python3 352MiB |
+-----------------------------------------------------------------------------------------+
5. HAMi代码分析
以代码commit为例:96adaec66c4472383108de2d18698b47f5e6e553
5.1 hami-scheduler调试环境
因为gpu环境在远程服务器端,所以利用dlv+golang来搭建远程调试环境.大体思路是:
- 在远程gpu服务器上用dlv启动hami-scheduler
- 把hami-scheduler相关的配置指向本地本地dlv启动的hami-scheduler服务
- 在远程gpu服务器上用dlv启动hami-scheduler
root@vgpu:~# nerdctl -n k8s.io cp <hami-scheduler-container-id>:/tls/tls.crt /root/tls/
root@vgpu:~# nerdctl -n k8s.io cp <hami-scheduler-container-id>:/tls/tls.key /root/tls/
dlv exec bin/scheduler --headless -l 0.0.0.0:2345 --api-version=2 -- \
--http_bind=0.0.0.0:9443 \
--cert_file=/root/tls/tls.crt \
--key_file=/root/tls/tls.key \
--scheduler-name=hami-scheduler \
--node-scheduler-policy=binpack \
--gpu-scheduler-policy=spread \
--device-config-file=/root/device-config.yaml
启动参数通过kubectl -n kube-system edit deployments.apps hami-scheduler可以查看,device-config.yaml文件通过nerdctl -n k8s.io cp <hami-scheduler-container-id>:/root/device-config.yaml获取。dlv debug直接调试源代码并自动编译(适合开发环境),而dlv exec调试已编译的二进制文件(适合生产环境,但需要编译时包含调试信息 -gcflags=“all=-N -l”),dlv exec直接作用于二进制,启动较快。HAMi代码库中有提供Makefile需要移除下-s -w参数,make build可以编译出包含调试信息的二进制文件。
- hami-webhook指向本地dlv启动的hami-scheduler服务
(base) root@vgpu:~# kubectl edit mutatingwebhookconfigurations.admissionregistration.k8s.io hami-webhook
# webhook限制强制使用https,复用证书,用127.0.0.1的地址
...
webhooks:
- admissionReviewVersions:
- v1beta1
clientConfig:
url: https://127.0.0.1:9443/webhook
...
- hami-scheduler extender指向本地dlv启动的hami-scheduler服务
(base) root@vgpu:~# kubectl -n kube-system edit cm hami-scheduler-newversion
...
apiVersion: v1
data:
config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
profiles:
- schedulerName: hami-scheduler
extenders:
- urlPrefix: "https://<dlv-local-ip>:9443"
filterVerb: filter
bindVerb: bind
nodeCacheCapable: true
weight: 1
httpTimeout: 30s
enableHTTPS: false
tlsConfig:
insecure: true
...
hami-scheduler deployment实际上包含两个container:一个是kube-scheduler原生调度器,一个是hami-scheduler自定义调度器;扩展调度器用的还是废弃的extender机制,并非scheduler framework。exterder机制虽有性能问题,但是使用起来比较简单。
- goland添加Go Remote Debugger指向:2345
5.2 hami-scheduler核心逻辑
hami-scheduler带的命令行参数
func init() {
// 禁用了命令行参数的自动排序,保持参数的定义顺序
rootCmd.Flags().SortFlags = false
rootCmd.PersistentFlags().SortFlags = false
rootCmd.Flags().StringVar(&config.HTTPBind, "http_bind", "127.0.0.1:8080", "http server bind address")
rootCmd.Flags().StringVar(&tlsCertFile, "cert_file", "", "tls cert file")
rootCmd.Flags().StringVar(&tlsKeyFile, "key_file", "", "tls key file")
rootCmd.Flags().StringVar(&config.SchedulerName, "scheduler-name", "", "the name to be added to pod.spec.schedulerName if not empty")
rootCmd.Flags().Int32Var(&config.DefaultMem, "default-mem", 0, "default gpu device memory to allocate")
rootCmd.Flags().Int32Var(&config.DefaultCores, "default-cores", 0, "default gpu core percentage to allocate")
rootCmd.Flags().Int32Var(&config.DefaultResourceNum, "default-gpu", 1, "default gpu to allocate")
rootCmd.Flags().StringVar(&config.NodeSchedulerPolicy, "node-scheduler-policy", util.NodeSchedulerPolicyBinpack.String(), "node scheduler policy")
rootCmd.Flags().StringVar(&config.GPUSchedulerPolicy, "gpu-scheduler-policy", util.GPUSchedulerPolicySpread.String(), "GPU scheduler policy")
rootCmd.Flags().StringVar(&config.MetricsBindAddress, "metrics-bind-address", ":9395", "The TCP address that the scheduler should bind to for serving prometheus metrics(e.g. 127.0.0.1:9395, :9395)")
// 区分了 Flags() 和 PersistentFlags():
// Flags():仅对当前命令有效的参数
// PersistentFlags():对当前命令及其子命令都有效的参数
rootCmd.Flags().StringToStringVar(&config.NodeLabelSelector, "node-label-selector", nil, "key=value pairs separated by commas")
rootCmd.PersistentFlags().AddGoFlagSet(device.GlobalFlagSet())
rootCmd.AddCommand(version.VersionCmd)
rootCmd.Flags().AddGoFlagSet(util.InitKlogFlags())
}
// 其它的全局命令行参数
func GlobalFlagSet() *flag.FlagSet {
fs := flag.NewFlagSet(os.Args[0], flag.ExitOnError)
ascend.ParseConfig(fs)
cambricon.ParseConfig(fs)
hygon.ParseConfig(fs)
iluvatar.ParseConfig(fs)
nvidia.ParseConfig(fs)
mthreads.ParseConfig(fs)
metax.ParseConfig(fs)
fs.BoolVar(&DebugMode, "debug", false, "debug mode")
fs.StringVar(&configFile, "device-config-file", "", "device config file")
klog.InitFlags(fs)
return fs
}
scheduler启动函数
func start() {
// 根据device-config初始化devices map
device.InitDevices()
// 初始化hami-scheduelr调度器
sher = scheduler.NewScheduler()
// 启动hami-scheduelr调度器
sher.Start()
// 停止调度器
defer sher.Stop()
// 这个函数的主要职责是:
// 1. 持续监控:
// 通过channel和定时器实现持续监控
// 响应节点变更事件和定时检查
// 2. 设备健康检查:
// 定期检查每个节点上的设备健康状态
// 处理不健康的设备(清理和移除)
// 3. 设备信息更新:
// 维护最新的节点设备信息
// 处理设备握手机制
// 更新调度器的设备缓存
// 4. 资源使用统计:
// 追踪并更新节点资源使用情况
// 这是调度器的核心组件之一,确保调度决策基于最新的节点和设备状态信息。
go sher.RegisterFromNodeAnnotations()
// 暴露metrics监控指标
go initMetrics(config.MetricsBindAddress)
// 启动一个http server,用于处理调度器请求
router := httprouter.New()
// 调度filter阶段请求
router.POST("/filter", routes.PredicateRoute(sher))
// 调度bind阶段请求
router.POST("/bind", routes.Bind(sher))
// webhook请求
router.POST("/webhook", routes.WebHookRoute())
// 健康检查请求
router.GET("/healthz", routes.HealthzRoute())
klog.Info("listen on ", config.HTTPBind)
if len(tlsCertFile) == 0 || len(tlsKeyFile) == 0 {
if err := http.ListenAndServe(config.HTTPBind, router); err != nil {
klog.Fatal("Listen and Serve error, ", err)
}
} else {
if err := http.ListenAndServeTLS(config.HTTPBind, tlsCertFile, tlsKeyFile, router); err != nil {
klog.Fatal("Listen and Serve error, ", err)
}
}
}
为什么要初始化GPU设备devices map?通过这种初始化机制,HAMi可以统一管理不同类型的GPU,为上层调度提供统一的设备抽象。需要维护一个设备注册表,记录所有支持的GPU。每个设备都需要实现Devices接口,提供以下核心功能:
- 资源分配和管理
- 设备健康检查
- 节点打分和筛选
- 设备锁定和释放
- 资源使用统计
// Devices接口定义了GPU设备的核心功能,从目前实现来看支持7种设备:nvidia、ascend、cambricon、hygon、iluvatar、mthreads、metax
type Devices interface {
CommonWord() string
MutateAdmission(ctr *corev1.Container, pod *corev1.Pod) (bool, error)
CheckHealth(devType string, n *corev1.Node) (bool, bool)
NodeCleanUp(nn string) error
GetNodeDevices(n corev1.Node) ([]*util.DeviceInfo, error)
CheckType(annos map[string]string, d util.DeviceUsage, n util.ContainerDeviceRequest) (bool, bool, bool)
// CheckUUID is check current device id whether in GPUUseUUID or GPUNoUseUUID set, return true is check success.
CheckUUID(annos map[string]string, d util.DeviceUsage) bool
LockNode(n *corev1.Node, p *corev1.Pod) error
ReleaseNodeLock(n *corev1.Node, p *corev1.Pod) error
GenerateResourceRequests(ctr *corev1.Container) util.ContainerDeviceRequest
PatchAnnotations(annoinput *map[string]string, pd util.PodDevices) map[string]string
CustomFilterRule(allocated *util.PodDevices, request util.ContainerDeviceRequest, toAllicate util.ContainerDevices, device *util.DeviceUsage) bool
ScoreNode(node *corev1.Node, podDevices util.PodSingleDevice, policy string) float32
AddResourceUsage(n *util.DeviceUsage, ctr *util.ContainerDevice) error
// This should not be associated with a specific device object
//ParseConfig(fs *flag.FlagSet)
}
func InitDevicesWithConfig(config *Config) {
// 初始化devices map
devices = make(map[string]Devices)
DevicesToHandle = []string{}
// 初始化nvidia设备
devices[nvidia.NvidiaGPUDevice] = nvidia.InitNvidiaDevice(config.NvidiaConfig)
// 初始化cambricon设备
devices[cambricon.CambriconMLUDevice] = cambricon.InitMLUDevice(config.CambriconConfig)
// 初始化hygon设备
devices[hygon.HygonDCUDevice] = hygon.InitDCUDevice(config.HygonConfig)
// 初始化iluvatar设备
devices[iluvatar.IluvatarGPUDevice] = iluvatar.InitIluvatarDevice(config.IluvatarConfig)
// 初始化mthreads设备
devices[mthreads.MthreadsGPUDevice] = mthreads.InitMthreadsDevice(config.MthreadsConfig)
// 初始化metax设备
devices[metax.MetaxGPUDevice] = metax.InitMetaxDevice(config.MetaxConfig)
// CommonWord函数,看起来像是设备别名转换
DevicesToHandle = append(DevicesToHandle, nvidia.NvidiaGPUCommonWord)
DevicesToHandle = append(DevicesToHandle, cambricon.CambriconMLUCommonWord)
DevicesToHandle = append(DevicesToHandle, hygon.HygonDCUCommonWord)
DevicesToHandle = append(DevicesToHandle, iluvatar.IluvatarGPUCommonWord)
DevicesToHandle = append(DevicesToHandle, mthreads.MthreadsGPUCommonWord)
DevicesToHandle = append(DevicesToHandle, metax.MetaxGPUCommonWord)
for _, dev := range ascend.InitDevices(config.VNPUs) {
devices[dev.CommonWord()] = dev
DevicesToHandle = append(DevicesToHandle, dev.CommonWord())
}
}
hami也会在集群中运行一个hami-scheduler的调度器,pod调度时,如何区分是集群内原有的调度器还是hami-scheduler?mutatingwebhook hami-webhook会指定pod调度器为hami-scheduler
// 创建一个webhook,用于处理pod调度请求
func NewWebHook() (*admission.Webhook, error) {
logf.SetLogger(klog.NewKlogr())
schema := runtime.NewScheme()
if err := clientgoscheme.AddToScheme(schema); err != nil {
return nil, err
}
decoder := admission.NewDecoder(schema)
wh := &admission.Webhook{Handler: &webhook{decoder: decoder}}
return wh, nil
}
// webhook结构体实现了Handler interface
func (h *webhook) Handle(_ context.Context, req admission.Request) admission.Response {
pod := &corev1.Pod{}
// 解码请求,获取pod信息
err := h.decoder.Decode(req, pod)
if err != nil {
klog.Errorf("Failed to decode request: %v", err)
return admission.Errored(http.StatusBadRequest, err)
}
// 检查pod是否有容器
if len(pod.Spec.Containers) == 0 {
klog.Warningf(template+" - Denying admission as pod has no containers", req.Namespace, req.Name, req.UID)
return admission.Denied("pod has no containers")
}
klog.Infof(template, req.Namespace, req.Name, req.UID)
hasResource := false
for idx, ctr := range pod.Spec.Containers {
c := &pod.Spec.Containers[idx]
// 检查容器是否为特权容器
if ctr.SecurityContext != nil {
if ctr.SecurityContext.Privileged != nil && *ctr.SecurityContext.Privileged {
klog.Warningf(template+" - Denying admission as container %s is privileged", req.Namespace, req.Name, req.UID, c.Name)
continue
}
}
// 检查容器是否为vgpu容器
for _, val := range device.GetDevices() {
// 调用设备接口的MutateAdmission方法,检查容器是否为vgpu容器
found, err := val.MutateAdmission(c, pod)
if err != nil {
klog.Errorf("validating pod failed:%s", err.Error())
return admission.Errored(http.StatusInternalServerError, err)
}
hasResource = hasResource || found
}
}
if !hasResource {
klog.Infof(template+" - Allowing admission for pod: no resource found", req.Namespace, req.Name, req.UID)
//return admission.Allowed("no resource found")
} else if len(config.SchedulerName) > 0 {
// 如果配置了scheduler-name,则设置pod调度器为hami-scheduler
pod.Spec.SchedulerName = config.SchedulerName
if pod.Spec.NodeName != "" {
klog.Infof(template+" - Pod already has node assigned", req.Namespace, req.Name, req.UID)
return admission.Denied("pod has node assigned")
}
}
marshaledPod, err := json.Marshal(pod)
if err != nil {
klog.Errorf(template+" - Failed to marshal pod, error: %v", req.Namespace, req.Name, req.UID, err)
return admission.Errored(http.StatusInternalServerError, err)
}
return admission.PatchResponseFromRaw(req.Object.Raw, marshaledPod)
}
vgpu pod的annotation是什么时候添加的?在scheduler filter阶段添加
// filter核心函数
func (s *Scheduler) Filter(args extenderv1.ExtenderArgs) (*extenderv1.ExtenderFilterResult, error) {
klog.InfoS("begin schedule filter", "pod", args.Pod.Name, "uuid", args.Pod.UID, "namespaces", args.Pod.Namespace)
// 用于统计Pod中容器的设备资源请求
nums := k8sutil.Resourcereqs(args.Pod)
total := 0
for _, n := range nums {
for _, k := range n {
total += int(k.Nums)
}
}
if total == 0 {
// 如果Pod中没有请求任何资源,则记录调度失败事件
klog.V(1).Infof("pod %v not find resource", args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, fmt.Errorf("does not request any resource"))
return &extenderv1.ExtenderFilterResult{
NodeNames: args.NodeNames,
FailedNodes: nil,
Error: "",
}, nil
}
annos := args.Pod.Annotations
// 从podManager维护的pods map中删除pod
s.delPod(args.Pod)
// 调度器中的重要函数,用于获取节点资源使用情况
nodeUsage, failedNodes, err := s.getNodesUsage(args.NodeNames, args.Pod)
if err != nil {
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
return nil, err
}
if len(failedNodes) != 0 {
klog.V(5).InfoS("getNodesUsage failed nodes", "nodes", failedNodes)
}
// 计算节点得分的函数
// 1. 获取节点调度策略
// 2. 遍历所有可用节点
// 3. 计算每个节点的基础得分
// 4. 检查容器的设备需求适配性
// 5. 根据策略调整最终得分
// 6. 记录符合要求的节点得分
// 计算逻辑说明:
// 分别计算三个维度的使用率:设备、核心、显存
// 每个维度的得分是使用量与总量的比值
// 最终得分是三个维度得分之和乘以权重
// 适配性检查,检查节点上的设备是否能满足容器的资源请求;如果适配成功,会在score.Devices中记录设备的分配方案
// fit, _ := fitInDevices(
// node, // 节点信息(包含该节点上的设备状态)
// n, // 容器的设备请求数量
// annos, // Pod 的注解信息
// task, // 待调度的 Pod
// &score.Devices // 输出参数:记录设备分配结果
// )
nodeScores, err := s.calcScore(nodeUsage, nums, annos, args.Pod, failedNodes)
if err != nil {
err := fmt.Errorf("calcScore failed %v for pod %v", err, args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
return nil, err
}
// 如果所有节点得分都不符合要求,则记录调度失败事件
if len((*nodeScores).NodeList) == 0 {
klog.V(4).Infof("All node scores do not meet for pod %v", args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, fmt.Errorf("no available node, all node scores do not meet"))
return &extenderv1.ExtenderFilterResult{
FailedNodes: failedNodes,
}, nil
}
klog.V(4).Infoln("nodeScores_len=", len((*nodeScores).NodeList))
// 对节点得分进行排序
sort.Sort(nodeScores)
// 获取得分最高的节点
m := (*nodeScores).NodeList[len((*nodeScores).NodeList)-1]
klog.Infof("schedule %v/%v to %v %v", args.Pod.Namespace, args.Pod.Name, m.NodeID, m.Devices)
annotations := make(map[string]string)
// 添加调度节点和调度时间到pod的annotation中
annotations[util.AssignedNodeAnnotations] = m.NodeID
// 添加调度时间到pod的annotation中
annotations[util.AssignedTimeAnnotations] = strconv.FormatInt(time.Now().Unix(), 10)
for _, val := range device.GetDevices() {
val.PatchAnnotations(&annotations, m.Devices)
}
//InRequestDevices := util.EncodePodDevices(util.InRequestDevices, m.devices)
//supportDevices := util.EncodePodDevices(util.SupportDevices, m.devices)
//maps.Copy(annotations, InRequestDevices)
//maps.Copy(annotations, supportDevices)
// 将pod添加到podManager维护的pods map中
s.addPod(args.Pod, m.NodeID, m.Devices)
// 更新pod的annotation
err = util.PatchPodAnnotations(args.Pod, annotations)
if err != nil {
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
s.delPod(args.Pod)
return nil, err
}
// 记录调度成功事件
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringSucceed, []string{m.NodeID}, nil)
// 返回调度结果
res := extenderv1.ExtenderFilterResult{NodeNames: &[]string{m.NodeID}}
return &res, nil
}
除了filter阶段,scheduler还有bind阶段,bind阶段是带有资源锁定的安全绑定过程,确保设备资源不会被重复分配,并在失败时能够正确清理资源。
hami-scheduler本身也是个controller,这个controller监听什么资源,然后reconcile处理什么逻辑?
func NewScheduler() *Scheduler {
klog.Info("New Scheduler")
// 初始化scheduler
s := &Scheduler{
stopCh: make(chan struct{}),
// 维护一个缓存map,保存节点GPU设备使用情况
cachedstatus: make(map[string]*NodeUsage),
nodeNotify: make(chan struct{}, 1),
}
// 初始化nodeManager,维护一个nodes map,key为node_id,value为节点GPU设备的信息
s.nodeManager.init()
// 初始化podManager,维护一个pods map,key为pod_id,value为pod GPU设备信息
s.podManager.init()
return s
}
// 启动controller
func (s *Scheduler) Start() {
// 初始化k8s clientSet
kubeClient, err := k8sutil.NewClient()
check(err)
s.kubeClient = kubeClient
// 初始化informerFactory,用于监听k8s资源变化
informerFactory := informers.NewSharedInformerFactoryWithOptions(s.kubeClient, time.Hour*1)
// 初始化podLister,用于获取pod信息
s.podLister = informerFactory.Core().V1().Pods().Lister()
// 初始化nodeLister,用于获取node信息
s.nodeLister = informerFactory.Core().V1().Nodes().Lister()
// 初始化podInformer,用于监听pod资源变化
informer := informerFactory.Core().V1().Pods().Informer()
// 添加pod资源事件处理函数
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
// onAddPod 处理 Pod 添加事件
// 1. 验证对象类型是否为 Pod
// 2. 检查 Pod 是否有指定节点的注解
// 3. 如果 Pod 处于终止状态则删除
// 4. 解析 Pod 的设备注解并添加到podManager维护的pods map中
AddFunc: s.onAddPod,
// onUpdatePod 处理 Pod 更新事件,走的还是onAddPod逻辑
UpdateFunc: s.onUpdatePod,
// onDelPod 处理 Pod 删除事件,从podManager维护的pods map中删除pod
DeleteFunc: s.onDelPod,
})
// 初始化nodeInformer,用于监听node资源变化
informerFactory.Core().V1().Nodes().Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
// 这三个事件函数都是向nodeNotify channel发送一个空结构体信号
// 这个设计的关键点:
// 1. 通知机制:
// nodeNotify是一个 channel,用于发送通知信号
// struct{}{}是一个空结构体,在Go中常用作信号传递(因为它不占用内存)
// 2. 触发更新:
// 这些函数与RegisterFromNodeAnnotations()方法配合工作
// 当节点发生任何变化时,都会触发重新扫描和同步节点状态
// 3. 统一处理:
// 所有节点事件(添加/更新/删除)都触发相同的通知
// 实际的节点状态更新逻辑在接收通知的地方统一处理
AddFunc: s.onAddNode,
UpdateFunc: s.onUpdateNode,
DeleteFunc: s.onDelNode,
})
// 启动informerFactory,开始监听k8s资源变化
informerFactory.Start(s.stopCh)
// 等待informerFactory缓存同步完成
informerFactory.WaitForCacheSync(s.stopCh)
// 添加其它的事件处理函数
s.addAllEventHandlers()
}
5.3 hami-device-plugin调试环境
远程gpu服务器上dlv启动hami-device-plugin,本地goland添加Go Remote Debugger指向:2346
NODE_NAME=vgpu NVIDIA_MIG_MONITOR_DEVICES=all HOOK_PATH=/usr/local \
dlv exec bin/nvidia-device-plugin --headless -l 0.0.0.0:2346 --api-version=2 -- \
--config-file=/root/device-config.yaml \
--mig-strategy=none \
--disable-core-limit=false \
-v=false
5.4 hami-device-plugin核心逻辑
在了解hami nvidia-device-plugin前,需要了解下nvidia-runtime、GPU Operator、k8s device plugin等
- nvidia-runtime:对应Docker环境,安装nvidia-container-toolkit组件,docker配置使用nvidia-runtime,启动容器时增加
--gpu参数;nvidia-container-toolkit根据NVIDIA_VISIBLE_DEVICES环境变量将GPU、驱动等相关文件挂载到容器里。 - k8s device plugin:对应k8s环境,Nvidia提供的一种k8s GPU实现方案
- GPU Operator:对应k8s环境,Nvidia提供的一种在Kubernetes环境中简化使用GPU的部署方案
device-plugin原理:device plugin学习笔记
实现一个device-plugin大致分为两部分:插件注册、kubelet调用插件(grpc调用,device-plugin做为grpc server启动)
// DevicePluginServer是device-plugin的server接口,定义了device-plugin需要实现的方法
// DevicePluginServer is the server API for DevicePlugin service.
type DevicePluginServer interface {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
GetDevicePluginOptions(context.Context, *Empty) (*DevicePluginOptions, error)
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
ListAndWatch(*Empty, DevicePlugin_ListAndWatchServer) error
// GetPreferredAllocation returns a preferred set of devices to allocate
// from a list of available ones. The resulting preferred allocation is not
// guaranteed to be the allocation ultimately performed by the
// devicemanager. It is only designed to help the devicemanager make a more
// informed allocation decision when possible.
GetPreferredAllocation(context.Context, *PreferredAllocationRequest) (*PreferredAllocationResponse, error)
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
Allocate(context.Context, *AllocateRequest) (*AllocateResponse, error)
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as resetting the device before making devices available to the container
PreStartContainer(context.Context, *PreStartContainerRequest) (*PreStartContainerResponse, error)
}
虽然接口定义了5个方法,但是HAMi nvidia-device-plugin只实现了Allocate、ListAndWatch,外加一个Register方法,所以重点关注这三个实现
- Register:插件注册到kubelet
- ListAndWatch:获取GPU设备信息,并上报给kubelet
- Allocate:分配GPU设备给容器
device-plugin启动函数
func start(c *cli.Context, flags []cli.Flag) error {
klog.Info("Starting FS watcher.")
// 获取节点名称
util.NodeName = os.Getenv(util.NodeNameEnvName)
// 创建一个文件系统监视器,用于监听kubelet设备插件路径的变化
watcher, err := newFSWatcher(kubeletdevicepluginv1beta1.DevicePluginPath)
if err != nil {
return fmt.Errorf("failed to create FS watcher: %v", err)
}
defer watcher.Close()
//device.InitDevices()
/*Loading config files*/
klog.Infof("Start working on node %s", util.NodeName)
klog.Info("Starting OS watcher.")
// 创建一个信号监听器,用于监听SIGHUP、SIGINT、SIGTERM、SIGQUIT信号
sigs := newOSWatcher(syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
var restarting bool
var restartTimeout <-chan time.Time
var plugins []plugin.Interface
restart:
// If we are restarting, stop plugins from previous run.
if restarting {
err := stopPlugins(plugins)
if err != nil {
return fmt.Errorf("error stopping plugins from previous run: %v", err)
}
}
klog.Info("Starting Plugins.")
// 启动插件
plugins, restartPlugins, err := startPlugins(c, flags, restarting)
if err != nil {
return fmt.Errorf("error starting plugins: %v", err)
}
if restartPlugins {
klog.Info("Failed to start one or more plugins. Retrying in 30s...")
// 设置重启超时时间
restartTimeout = time.After(30 * time.Second)
}
// 设置重启标志
restarting = true
// Start an infinite loop, waiting for several indicators to either log
// some messages, trigger a restart of the plugins, or exit the program.
for {
select {
// If the restart timeout has expired, then restart the plugins
case <-restartTimeout:
goto restart
// Detect a kubelet restart by watching for a newly created
// 'kubeletdevicepluginv1beta1.KubeletSocket' file. When this occurs, restart this loop,
// restarting all of the plugins in the process.
case event := <-watcher.Events:
// 监听kubelet设备插件路径的变化
if event.Name == kubeletdevicepluginv1beta1.KubeletSocket && event.Op&fsnotify.Create == fsnotify.Create {
klog.Infof("inotify: %s created, restarting.", kubeletdevicepluginv1beta1.KubeletSocket)
goto restart
}
// Watch for any other fs errors and log them.
case err := <-watcher.Errors:
klog.Errorf("inotify: %s", err)
// Watch for any signals from the OS. On SIGHUP, restart this loop,
// restarting all of the plugins in the process. On all other
// signals, exit the loop and exit the program.
case s := <-sigs:
switch s {
case syscall.SIGHUP:
klog.Info("Received SIGHUP, restarting.")
goto restart
default:
klog.Infof("Received signal \"%v\", shutting down.", s)
goto exit
}
}
}
exit:
// 停止插件
err = stopPlugins(plugins)
if err != nil {
return fmt.Errorf("error stopping plugins: %v", err)
}
return nil
}
启动函数除了启动插件外,还启动监视器来监听/var/lib/kubelet/device-plugins/kubelet.sock的变化,每次重启kubelet,kubelet.sock都会被重新创建,kubelet是通过map来存储device-plugin的注册信息,所以每次kubelet重启,device-plugin都需要重新注册(也跟着重启)
HAMi作为GPU管理框架,针对插件的启动、停止,自身抽象了一套接口:
// Interface defines the API for the plugin package
type Interface interface {
Devices() rm.Devices
Start() error
Stop() error
}
插件Start实现包含:plugin.Serve、plugin.Register、plugin.WatchAndRegister
// 在插件注册前,plugin.Serve会先启动插件grpc server
// Serve starts the gRPC server of the device plugin.
func (plugin *NvidiaDevicePlugin) Serve() error {
// 删除已存在的socket文件
os.Remove(plugin.socket)
// 监听socket文件
sock, err := net.Listen("unix", plugin.socket)
if err != nil {
return err
}
// 注册设备插件的gRPC服务器
kubeletdevicepluginv1beta1.RegisterDevicePluginServer(plugin.server, plugin)
// 启动grpc server
go func() {
lastCrashTime := time.Now()
restartCount := 0
for {
klog.Infof("Starting GRPC server for '%s'", plugin.rm.Resource())
err := plugin.server.Serve(sock)
if err == nil {
break
}
klog.Infof("GRPC server for '%s' crashed with error: %v", plugin.rm.Resource(), err)
// restart if it has not been too often
// i.e. if server has crashed more than 5 times and it didn't last more than one hour each time
if restartCount > 5 {
// quit
klog.Fatalf("GRPC server for '%s' has repeatedly crashed recently. Quitting", plugin.rm.Resource())
}
timeSinceLastCrash := time.Since(lastCrashTime).Seconds()
lastCrashTime = time.Now()
if timeSinceLastCrash > 3600 {
// it has been one hour since the last crash.. reset the count
// to reflect on the frequency
restartCount = 1
} else {
restartCount++
}
}
}()
// 验证连接到device-plugin
conn, err := plugin.dial(plugin.socket, 5*time.Second)
if err != nil {
return err
}
// 关闭连接
conn.Close()
return nil
}
plugin.Register实现
// Register registers the device plugin for the given resourceName with Kubelet.
func (plugin *NvidiaDevicePlugin) Register() error {
// 连接到kubelet
conn, err := plugin.dial(kubeletdevicepluginv1beta1.KubeletSocket, 5*time.Second)
if err != nil {
return err
}
defer conn.Close()
// 创建一个注册客户端
client := kubeletdevicepluginv1beta1.NewRegistrationClient(conn)
// 创建一个注册请求
reqt := &kubeletdevicepluginv1beta1.RegisterRequest{
Version: kubeletdevicepluginv1beta1.Version,
Endpoint: path.Base(plugin.socket),
// 资源名称
ResourceName: string(plugin.rm.Resource()),
// 设备插件选项
Options: &kubeletdevicepluginv1beta1.DevicePluginOptions{
GetPreferredAllocationAvailable: false,
},
}
// 发送注册请求
_, err = client.Register(context.Background(), reqt)
if err != nil {
return err
}
return nil
}
plugin.WatchAndRegister实现
func (plugin *NvidiaDevicePlugin) WatchAndRegister() {
klog.Info("Starting WatchAndRegister")
errorSleepInterval := time.Second * 5
successSleepInterval := time.Second * 30
for {
// annotation格式形如:
// annotations:
// hami.io/node-nvidia-register: 'GPU-a8243209-6b70-5b3d-de52-1aaafc1495fc,10,24576,100,NVIDIA-NVIDIA GeForce RTX 3090,0,true,0,:'
// 通过nvml库获取GPU信息,并更新到Node的annotation上
err := plugin.RegistrInAnnotation()
if err != nil {
klog.Errorf("Failed to register annotation: %v", err)
klog.Infof("Retrying in %v seconds...", errorSleepInterval)
time.Sleep(errorSleepInterval)
} else {
klog.Infof("Successfully registered annotation. Next check in %v seconds...", successSleepInterval)
time.Sleep(successSleepInterval)
}
}
}
这里device-plugin是直接和k8s-apiserver交互,更新Node信息,hami.io/node-nvidia-register的annotation信息,后面hami-scheduler的RegisterFromNodeAnnotations函数会根据annotation信息进行调度
插件ListAndWatch实现(启动nvidi-device-plugin时进入)
// ListAndWatch lists devices and update that list according to the health status
func (plugin *NvidiaDevicePlugin) ListAndWatch(e *kubeletdevicepluginv1beta1.Empty, s kubeletdevicepluginv1beta1.DevicePlugin_ListAndWatchServer) error {
// 发送GPU设备信息给kubelet
s.Send(&kubeletdevicepluginv1beta1.ListAndWatchResponse{Devices: plugin.apiDevices()})
for {
select {
case <-plugin.stop:
return nil
case d := <-plugin.health:
// FIXME: there is no way to recover from the Unhealthy state.
d.Health = kubeletdevicepluginv1beta1.Unhealthy
klog.Infof("'%s' device marked unhealthy: %s", plugin.rm.Resource(), d.ID)
// 发送GPU设备信息给kubelet
s.Send(&kubeletdevicepluginv1beta1.ListAndWatchResponse{Devices: plugin.apiDevices()})
}
}
}
// plugin.apiDevices最终会进入到GetPluginDevices函数
// GetPluginDevices returns the plugin Devices from all devices in the Devices
func (ds Devices) GetPluginDevices(count uint) []*kubeletdevicepluginv1beta1.Device {
var res []*kubeletdevicepluginv1beta1.Device
// 如果GPU不是MIG模式,则需要根据count,复制多个device,每个device的ID不同
if !strings.Contains(ds.GetIDs()[0], "MIG") {
for _, dev := range ds {
// count取值来自--device-split-count参数,单卡同时运行多少个任务,一般推荐10以上
for i := uint(0); i < count; i++ {
id := fmt.Sprintf("%v-%v", dev.ID, i)
// 根据count,复制多个device,每个device的ID不同
res = append(res, &kubeletdevicepluginv1beta1.Device{
ID: id,
Health: dev.Health,
Topology: nil,
})
}
}
} else {
// 如果GPU是MIG模式,则直接返回所有GPU设备信息
for _, d := range ds {
res = append(res, &d.Device)
}
}
// 返回GPU设备信息
return res
}
这里ds Devices参数是从哪里传入的?在pluginManager初始化的时候,最终b.buildGPUDeviceMap传入的
# mig-strategies为none时
pluginManager.GetPlugins -> rm.NewNVMLResourceManagers -> NewDeviceMap -> b.build
-> b.buildDeviceMapFromConfigResources -> b.buildGPUDeviceMap
NVIDIA设备插件中用于构建GPU设备映射的函数
// buildGPUDeviceMap builds a map of resource names to GPU devices
func (b *deviceMapBuilder) buildGPUDeviceMap() (DeviceMap, error) {
// 创建一个空的设备映射
devices := make(DeviceMap)
// 遍历所有 GPU 设备
b.VisitDevices(func(i int, gpu device.Device) error {
// 获取 GPU 的产品名称
name, ret := gpu.GetName()
if ret != nvml.SUCCESS {
return fmt.Errorf("error getting product name for GPU: %v", ret)
}
// 检查 GPU 是否启用了 MIG (Multi-Instance GPU) 功能
migEnabled, err := gpu.IsMigEnabled()
if err != nil {
return fmt.Errorf("error checking if MIG is enabled on GPU: %v", err)
}
// 如果 GPU 启用了 MIG 且 MIG 策略不是 "None",则跳过这个 GPU
// 因为 MIG 启用的 GPU 将由 buildMigDeviceMap 函数处理
if migEnabled && *b.config.Flags.MigStrategy != spec.MigStrategyNone {
return nil
}
// 遍历配置中定义的 GPU 资源
for _, resource := range b.config.Resources.GPUs {
// 检查 GPU 名称是否匹配资源模式
if resource.Pattern.Matches(name) {
// 如果匹配,创建新的 GPU 设备条目
index, info := newGPUDevice(i, gpu)
return devices.setEntry(resource.Name, index, info)
}
}
// 如果 GPU 名称不匹配任何资源模式,返回错误
return fmt.Errorf("GPU name '%v' does not match any resource patterns", name)
})
return devices, nil
}
插件Allocate实现(pod挂载GPU设备时进入)
// Allocate which return list of devices.
func (plugin *NvidiaDevicePlugin) Allocate(ctx context.Context, reqs *kubeletdevicepluginv1beta1.AllocateRequest) (*kubeletdevicepluginv1beta1.AllocateResponse, error) {
klog.InfoS("Allocate", "request", reqs)
// 创建一个AllocateResponse对象
responses := kubeletdevicepluginv1beta1.AllocateResponse{}
// 获取当前节点名称
nodename := os.Getenv(util.NodeNameEnvName)
// 获取当前挂载的pod
current, err := util.GetPendingPod(ctx, nodename)
if err != nil {
//nodelock.ReleaseNodeLock(nodename, NodeLockNvidia, current)
return &kubeletdevicepluginv1beta1.AllocateResponse{}, err
}
klog.Infof("Allocate pod name is %s/%s, annotation is %+v", current.Namespace, current.Name, current.Annotations)
// 遍历pod的容器请求
for idx, req := range reqs.ContainerRequests {
// If the devices being allocated are replicas, then (conditionally)
// error out if more than one resource is being allocated.
// 如果请求的设备ID包含MIG,则需要检查是否启用了时间切片,并且请求的设备ID数量大于1
if strings.Contains(req.DevicesIDs[0], "MIG") {
if plugin.config.Sharing.TimeSlicing.FailRequestsGreaterThanOne && rm.AnnotatedIDs(req.DevicesIDs).AnyHasAnnotations() {
if len(req.DevicesIDs) > 1 {
device.PodAllocationFailed(nodename, current, NodeLockNvidia)
return nil, fmt.Errorf("request for '%v: %v' too large: maximum request size for shared resources is 1", plugin.rm.Resource(), len(req.DevicesIDs))
}
}
for _, id := range req.DevicesIDs {
if !plugin.rm.Devices().Contains(id) {
device.PodAllocationFailed(nodename, current, NodeLockNvidia)
return nil, fmt.Errorf("invalid allocation request for '%s': unknown device: %s", plugin.rm.Resource(), id)
}
}
response, err := plugin.getAllocateResponse(req.DevicesIDs)
if err != nil {
device.PodAllocationFailed(nodename, current, NodeLockNvidia)
return nil, fmt.Errorf("failed to get allocate response: %v", err)
}
responses.ContainerResponses = append(responses.ContainerResponses, response)
} else {
// 如果请求的设备ID不包含MIG,则需要获取下一个设备请求
currentCtr, devreq, err := GetNextDeviceRequest(nvidia.NvidiaGPUDevice, *current)
klog.Infoln("deviceAllocateFromAnnotation=", devreq)
if err != nil {
device.PodAllocationFailed(nodename, current, NodeLockNvidia)
return &kubeletdevicepluginv1beta1.AllocateResponse{}, err
}
// 检查设备数量是否匹配
if len(devreq) != len(reqs.ContainerRequests[idx].DevicesIDs) {
device.PodAllocationFailed(nodename, current, NodeLockNvidia)
return &kubeletdevicepluginv1beta1.AllocateResponse{}, errors.New("device number not matched")
}
// 获取容器设备字符串数组,通过设置NVIDIA_VISIBLE_DEVICES环境变量,将GPU设备ID传递给容器
response, err := plugin.getAllocateResponse(plugin.GetContainerDeviceStrArray(devreq))
if err != nil {
return nil, fmt.Errorf("failed to get allocate response: %v", err)
}
// 清除下一个设备类型从annotation
err = EraseNextDeviceTypeFromAnnotation(nvidia.NvidiaGPUDevice, *current)
if err != nil {
device.PodAllocationFailed(nodename, current, NodeLockNvidia)
return &kubeletdevicepluginv1beta1.AllocateResponse{}, err
}
// 如果操作模式不是MIG,则需要设置CUDA_DEVICE_MEMORY_LIMIT、CUDA_DEVICE_SM_LIMIT、CUDA_DEVICE_MEMORY_SHARED_CACHE、CUDA_OVERSUBSCRIBE、CUDA_DISABLE_CONTROL等环境变量
if plugin.operatingMode != "mig" {
for i, dev := range devreq {
limitKey := fmt.Sprintf("CUDA_DEVICE_MEMORY_LIMIT_%v", i)
response.Envs[limitKey] = fmt.Sprintf("%vm", dev.Usedmem)
}
response.Envs["CUDA_DEVICE_SM_LIMIT"] = fmt.Sprint(devreq[0].Usedcores)
response.Envs["CUDA_DEVICE_MEMORY_SHARED_CACHE"] = fmt.Sprintf("%s/vgpu/%v.cache", hostHookPath, uuid.New().String())
if plugin.schedulerConfig.DeviceMemoryScaling > 1 {
response.Envs["CUDA_OVERSUBSCRIBE"] = "true"
}
if plugin.schedulerConfig.DisableCoreLimit {
response.Envs[util.CoreLimitSwitch] = "disable"
}
// 删除容器缓存目录
cacheFileHostDirectory := fmt.Sprintf("%s/vgpu/containers/%s_%s", hostHookPath, current.UID, currentCtr.Name)
os.RemoveAll(cacheFileHostDirectory)
// 创建容器缓存目录
os.MkdirAll(cacheFileHostDirectory, 0777)
os.Chmod(cacheFileHostDirectory, 0777)
// 创建vgpulock目录
os.MkdirAll("/tmp/vgpulock", 0777)
// 设置vgpulock目录权限
os.Chmod("/tmp/vgpulock", 0777)
response.Mounts = append(response.Mounts,
// 挂载libvgpu.so
&kubeletdevicepluginv1beta1.Mount{ContainerPath: fmt.Sprintf("%s/vgpu/libvgpu.so", hostHookPath),
HostPath: hostHookPath + "/vgpu/libvgpu.so",
ReadOnly: true},
// 挂载容器缓存目录
&kubeletdevicepluginv1beta1.Mount{ContainerPath: fmt.Sprintf("%s/vgpu", hostHookPath),
HostPath: cacheFileHostDirectory,
ReadOnly: false},
// 挂载vgpulock目录
&kubeletdevicepluginv1beta1.Mount{ContainerPath: "/tmp/vgpulock",
HostPath: "/tmp/vgpulock",
ReadOnly: false},
)
// 检查CUDA_DISABLE_CONTROL环境变量是否存在
found := false
for _, val := range currentCtr.Env {
// 如果环境变量是CUDA_DISABLE_CONTROL,则跳过
if strings.Compare(val.Name, "CUDA_DISABLE_CONTROL") == 0 {
// if env existed but is set to false or can not be parsed, ignore
// 将环境变量值转换为布尔值
t, _ := strconv.ParseBool(val.Value)
// 如果环境变量值为false,则跳过
if !t {
continue
}
// only env existed and set to true, we mark it "found"
found = true
break
}
}
// 如果CUDA_DISABLE_CONTROL环境变量不存在,则需要预加载链接库
if !found {
// 预加载链接库
response.Mounts = append(response.Mounts, &kubeletdevicepluginv1beta1.Mount{ContainerPath: "/etc/ld.so.preload",
HostPath: hostHookPath + "/vgpu/ld.so.preload",
ReadOnly: true},
)
}
// 检查vgpu license是否存在
_, err = os.Stat(fmt.Sprintf("%s/vgpu/license", hostHookPath))
if err == nil {
// 挂载vgpu license
response.Mounts = append(response.Mounts, &kubeletdevicepluginv1beta1.Mount{
ContainerPath: "/tmp/license",
HostPath: fmt.Sprintf("%s/vgpu/license", hostHookPath),
ReadOnly: true,
})
// 挂载vgpuvalidator
response.Mounts = append(response.Mounts, &kubeletdevicepluginv1beta1.Mount{
ContainerPath: "/usr/bin/vgpuvalidator",
HostPath: fmt.Sprintf("%s/vgpu/vgpuvalidator", hostHookPath),
ReadOnly: true,
})
}
}
// 将响应添加到响应列表中
responses.ContainerResponses = append(responses.ContainerResponses, response)
}
}
klog.Infoln("Allocate Response", responses.ContainerResponses)
// 标记pod分配成功
device.PodAllocationTrySuccess(nodename, nvidia.NvidiaGPUDevice, NodeLockNvidia, current)
return &responses, nil
}
这些环境变量如何生效? cuda天生支持的?是HAMi-core能够解析自定义的CUDA_xxx环境变量,而NVIDIA_VISIBLE_DEVICES是nvidia-container-toolkit支持的
NVIDIA_VISIBLE_DEVICES -> GPU-a8243209-6b70-5b3d-de52-1aaafc1495fc
CUDA_DEVICE_MEMORY_LIMIT_0 -> 3000m
CUDA_DEVICE_SM_LIMIT -> 25
CUDA_DEVICE_MEMORY_SHARED_CACHE -> /usr/local/vgpu/55202346-8648-4a49-9037-51b28eeb74ba.cache
NVIDIA_VISIBLE_DEVICES环境变量在nvidia-container-toolkit源码中nvidia-container-runtime服务会根据它用于获取NVIDIA GPU设备。
const (
// NVIDIA_VISIBLE_DEVICES变量
EnvVarNvidiaVisibleDevices = "NVIDIA_VISIBLE_DEVICES"
)
func (i CUDA) VisibleDevicesFromEnvVar() []string {
return i.DevicesFromEnvvars(EnvVarNvidiaVisibleDevices).List()
}
// DevicesFromEnvvars returns the devices requested by the image through environment variables
func (i CUDA) DevicesFromEnvvars(envVars ...string) VisibleDevices {
// 从指定的环境变量中获取并合并所有设备信息
var isSet bool // 标记是否有环境变量被设置
var devices []string // 存储所有找到的设备
requested := make(map[string]bool) // 用于追踪请求的设备(避免重复)
// 遍历所有传入的环境变量
for _, envVar := range envVars {
if devs, ok := i.env[envVar]; ok {
isSet = true // 标记找到了至少一个环境变量
// 解析环境变量值,按逗号分割
for _, d := range strings.Split(devs, ",") {
trimmed := strings.TrimSpace(d) // 去除空白字符
if len(trimmed) == 0 {
continue // 跳过空值
}
devices = append(devices, trimmed) // 添加到设备列表
requested[trimmed] = true // 记录该设备已被请求
}
}
}
// 特殊情况处理:
// 1. 如果是传统镜像且没有设置环境变量:返回"all"
if !isSet && len(devices) == 0 && i.IsLegacy() {
return NewVisibleDevices("all")
}
// 2. 如果没有找到设备或明确要求"void":返回"void"
if len(devices) == 0 || requested["void"] {
return NewVisibleDevices("void")
}
// 返回找到的所有设备
return NewVisibleDevices(devices...)
}
5.5 hami-core核心逻辑
libvgpu.so替换完为什么就生效?在Linux下预加载链接库有好几种方式,动态链接库加载优先级从高到低:
LD_PRELOAD > /etc/ld.so.preload > LD_LIBRARY_PATH > /etc/ld.so.conf.d/.conf > 默认系统路径(/lib, /usr/lib)
通过/etc/ld.so.preload定义,确保libvgpu.so肯定会被加载。cuda api的请求如何劫持?这部分逻辑定义在HAMi-core实现里,HAMi-core主要实现是在libvgpu.c文件里,实现了一个虚拟GPU库的核心功能。
核心功能:
- 实现了一个动态链接库劫持(hook)系统,用于拦截和重写CUDA和NVML相关的函数调用
- 管理GPU资源的虚拟化和分配
- 提供多进程间的GPU内存和利用率限制
CUDA API主要分为三大类:
- CUDA Runtime API:最常用、最高层的API,以cuda为前缀,头文件cuda_runtime.h;用于普通CUDA应用开发
- CUDA Driver API: 底层API,以cu为前缀,头文件:cuda.h;用于底层控制/动态加载
- NVIDIA Management Library (NVML):系统级管理API,以nvml为前缀,头文件:nvml.h;用于系统监控/管理
Runtime API --> Driver API --> 硬件
^
|
NVML (系统管理)
hami-core劫持的请求实际上是cuda-runtime调用cuda-driver的请求
+--------------+ +-----------------+
| Nvidia GPU | | CUDA Application|
+------+-------+ +---------+-------+
^ |
| v
+--------------+ +-----------------+
|Nvidia Driver | | CUDA Library |
+------+-------+ +---------+-------+
^ |
| v
+--------------+ +-----------------+
| CUDA Driver | | CUDA Runtime |
+--------------+ +---------+-------+
^ |
| v
| +-----------------+
+------------------+ HAMi-Core |
+-----------------+
劫持机制的关键点:
- 符号拦截:
- 当程序调用CUDA或NVML函数时,底层会通过dlsym查找符号
- 通过重写dlsym,我们可以拦截这些查找请求
- 根据符号名称前缀(“cu” 或 “nvml”)来识别目标函数
- 函数重写:
- 在劫持函数中,我们重写了CUDA和NVML函数的实现
- 这些重写后的函数会执行虚拟化或限制逻辑
- 例如,在CUDA函数中,我们可能模拟了GPU内存的虚拟化
- 在NVML函数中,我们可能模拟了GPU利用率的限制
// dlsym函数的重写
FUNC_ATTR_VISIBLE void* dlsym(void* handle, const char* symbol) {
pthread_once(&dlsym_init_flag, init_dlsym);
// 1. 初始化真实的dlsym
if (real_dlsym == NULL) {
real_dlsym = dlvsym(RTLD_NEXT, "dlsym", "GLIBC_2.2.5");
if (real_dlsym == NULL) {
real_dlsym = _dl_sym(RTLD_NEXT, "dlsym", dlsym);
}
}
// 2. 处理RTLD_NEXT的特殊情况
if (handle == RTLD_NEXT) {
void *h = real_dlsym(RTLD_NEXT, symbol);
// 防止递归调用
int tid = pthread_self();
pthread_mutex_lock(&dlsym_lock);
if (check_dlmap(tid, h)) {
h = NULL;
}
pthread_mutex_unlock(&dlsym_lock);
return h;
}
// 3. 劫持CUDA函数
if (symbol[0] == 'c' && symbol[1] == 'u') {
pthread_once(&pre_cuinit_flag, preInit);
// 调用__dlsym_hook_section函数,返回劫持后的CUDA函数
void* f = __dlsym_hook_section(handle, symbol);
if (f != NULL)
return f;
}
// 4. 劫持NVML函数
#ifdef HOOK_NVML_ENABLE
if (symbol[0] == 'n' && symbol[1] == 'v' &&
symbol[2] == 'm' && symbol[3] == 'l') {
// 调用__dlsym_hook_section_nvml函数,返回劫持后的NVML函数
void* f = __dlsym_hook_section_nvml(handle, symbol);
if (f != NULL)
return f;
}
#endif
// 5. 其他情况使用真实的 dlsym
return real_dlsym(handle, symbol);
}
// __dlsym_hook_section hook实现
void* __dlsym_hook_section(void* handle, const char* symbol) {
// 遍历所有需要劫持的CUDA函数
for (it = 0; it < CUDA_ENTRY_END; it++) {
if (strcmp(cuda_library_entry[it].name, symbol) == 0) {
if (cuda_library_entry[it].fn_ptr == NULL) {
return NULL;
} else {
break;
}
}
}
// 使用宏定义批量劫持函数
DLSYM_HOOK_FUNC(cuCtxGetDevice);
DLSYM_HOOK_FUNC(cuCtxCreate);
// ... 更多函数劫持
}
// __dlsym_hook_section_nvml hook实现
void* __dlsym_hook_section_nvml(void* handle, const char* symbol) {
// 使用宏定义批量劫持函数
DLSYM_HOOK_FUNC(nvmlInit);
/** nvmlShutdown */
DLSYM_HOOK_FUNC(nvmlShutdown);
/** nvmlErrorString */
DLSYM_HOOK_FUNC(nvmlErrorString);
/** nvmlDeviceGetHandleByIndex */
DLSYM_HOOK_FUNC(nvmlDeviceGetHandleByIndex);
// ... 更多函数劫持
return NULL;
}
DLSYM_HOOK_FUNC 是一个宏,用于动态符号链接钩子函数,它的基本工作流程是:
- 检查请求的符号名称是否匹配目标函数
- 如果匹配,返回一个钩子函数的指针,而不是原始函数
- 这允许程序在原始函数被调用之前或之后插入自定义代码
// DLSYM_HOOK_FUNC宏定义,用于批量劫持函数
#if defined(DLSYM_HOOK_DEBUG)
#define DLSYM_HOOK_FUNC(f) \
if (0 == strcmp(symbol, #f)) { \
LOG_DEBUG("Detect dlsym for %s\n", #f); \
return (void*) f; } \
#else
#define DLSYM_HOOK_FUNC(f) \
if (0 == strcmp(symbol, #f)) { \
return (void*) f; } \
#endif
这种劫持机制的优点是:
- 对应用程序透明,不需要修改源代码
- 可以完全控制 GPU 资源的分配和使用
- 可以实现细粒度的资源管理和监控
- 支持动态调整和策略更新
缺点是:
- 需要维护完整的函数映射表
- 版本更新时需要同步更新劫持函数
- 需要处理复杂的线程安全和递归问题
- 可能影响性能(额外的函数调用开销)
K8s yaml文件中的显存限制和gpu core限制,hami-core具体是如何处理的?
...
resources:
limits:
nvidia.com/gpumem: 3000
nvidia.com/gpucores: 25
hami -> nvidia.com/gpumem -> CUDA_DEVICE_MEMORY_LIMIT_0=3000m -> hami-core(libvgpu.so)
hami -> nvidia.com/gpucores -> CUDA_DEVICE_SM_LIMIT=25 -> hami-core(libvgpu.so)
通过一系列转化后,在hami的源码中可以找到,最终传给hami-core的是这两个环境变量CUDA_DEVICE_MEMORY_LIMIT_0和CUDA_DEVICE_SM_LIMIT,CUDA_DEVICE_MEMORY_LIMIT_i是动态环境变量. 在HAMi-core/src/multiprocess/multiprocess_memory_limit.c源码中有对应的处理逻辑,在进程初始化时通过ensure_initialized()调用,用于初始化共享内存区域
ensure_initialized -> initialized -> try_create_shrreg -> do_init_device_memory_limits(显存限制)
|
do_init_device_sm_limits(core利用率限制)
// 共享区域信息
typedef struct {
int32_t initialized_flag; // 初始化标志
uint32_t major_version; // 主版本号
uint32_t minor_version; // 次版本号
sem_t sem; // 信号量
uint64_t limit[CUDA_DEVICE_MAX_COUNT]; // 设备内存限制
uint64_t sm_limit[CUDA_DEVICE_MAX_COUNT]; // SM限制
shrreg_proc_slot_t procs[SHARED_REGION_MAX_PROCESS_NUM]; // 进程信息数组
int proc_num; // 进程数量
int utilization_switch; // 利用率开关
int recent_kernel; // 最近kernel信息
int priority; // 优先级
} shared_region_t;
do_init_device_memory_limits(region->limit, CUDA_DEVICE_MAX_COUNT); 往共享内存区域region写入显存限制,为了方便验证测试,直接设置这两个环境变量,通过nvidia-smi查看,设置LIBCUDA_LOG_LEVEL=4,可以查看hami-core打印的 debug日志,比如进到哪个cuda、nvml函数了
# 为挂载的设备添加1GiB内存限制并将最大SM利用率设置为50%
export LD_PRELOAD=./libvgpu.so
export CUDA_DEVICE_MEMORY_LIMIT=1g
export CUDA_DEVICE_SM_LIMIT=50
(base) root@vgpu:/libvgpu/build# LIBCUDA_LOG_LEVEL=4 nvidia-smi
[HAMI-core Debug(17398:140432464095040:libvgpu.c:56)]: init_dlsym
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlInitWithFlags
[HAMI-core Debug(17398:140432464095040:hook.c:442)]: nvmlInitWithFlags
[HAMI-core Debug(17398:140432464095040:hook.c:296)]: loading nvmlInit:0
...
[HAMI-core Debug(17398:140432464095040:multiprocess_memory_limit.c:777)]: shrreg created
[HAMI-core Debug(17398:140432464095040:device.c:94)]: into cuDriverGetVersion__
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym cuDriverGetVersion
[HAMI-core Debug(17398:140432464095040:device.c:99)]: Hijacking cuDriverGetVersion
[HAMI-core Info(17398:140432464095040:device.c:102)]: driver version=12040
Mon Jan 20 16:55:21 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.135 Driver Version: 550.135 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlDeviceGetIndex
...
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlDeviceGetMemoryInfo_v2
[HAMI-core Debug(17398:140432464095040:hook.c:321)]: into nvmlDeviceGetMemoryInfo
[HAMI-core Debug(17398:140432464095040:hook.c:328)]: Hijacking nvmlDeviceGetMemoryInfo_v2
[HAMI-core Debug(17398:140432464095040:hook.c:330)]: origin_free=25769803776 total=4192904278781722664
[HAMI-core Debug(17398:140432464095040:hook.c:268)]: Hijacking nvmlDeviceGetIndex
[HAMI-core Debug(17398:140432464095040:hook.c:437)]: Hijacking nvmlDeviceGetCount_v2
[HAMI-core Info(17398:140432464095040:multiprocess_memory_limit.c:289)]: get_gpu_memory_usage dev=0
[HAMI-core Info(17398:140432464095040:multiprocess_memory_limit.c:296)]: dev=0 pid=17398 host pid=0 i=0
[HAMI-core Debug(17398:140432464095040:multiprocess_memory_limit.c:883)]: get_current_device_memory_usage:tick=15 result=0
[HAMI-core Debug(17398:140432464095040:multiprocess_memory_limit.c:275)]: get_gpu_memory_monitor dev=0
[HAMI-core Debug(17398:140432464095040:multiprocess_memory_limit.c:281)]: dev=0 i=0,0
[HAMI-core Debug(17398:140432464095040:hook.c:338)]: usage=0 limit=1073741824 monitor=0
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlDeviceGetUtilizationRates
[HAMI-core Debug(17398:140432464095040:nvml_entry.c:753)]: Hijacking nvmlDeviceGetUtilizationRates
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlDeviceGetComputeMode
[HAMI-core Debug(17398:140432464095040:nvml_entry.c:220)]: Hijacking nvmlDeviceGetComputeMode
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlDeviceGetMigMode
[HAMI-core Debug(17398:140432464095040:nvml_entry.c:1445)]: Hijacking nvmlDeviceGetMigMode
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:00:05.0 Off | N/A |
| 0% 27C P8 7W / 370W | 0MiB / 1024MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
[HAMI-core Debug(17398:140432464095040:nvml_entry.c:1445)]: Hijacking nvmlDeviceGetMigMode
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlDeviceGetVirtualizationMode
[HAMI-core Debug(17398:140432464095040:nvml_entry.c:798)]: Hijacking nvmlDeviceGetVirtualizationMode
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlDeviceGetMaxMigDeviceCount
[HAMI-core Debug(17398:140432464095040:nvml_entry.c:1422)]: Hijacking nvmlDeviceGetMaxMigDeviceCount
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlDeviceIsMigDeviceHandle
[HAMI-core Debug(17398:140432464095040:nvml_entry.c:1467)]: Hijacking nvmlDeviceIsMigDeviceHandle
[HAMI-core Debug(17398:140432464095040:hook.c:268)]: Hijacking nvmlDeviceGetIndex
| No running processes found |
+-----------------------------------------------------------------------------------------+
...
[HAMI-core Debug(17398:140432464095040:libvgpu.c:79)]: into dlsym nvmlShutdown
[HAMI-core Debug(17398:140432464095040:nvml_entry.c:32)]: Hijacking nvmlShutdown
[HAMI-core Msg(17398:140432464095040:multiprocess_memory_limit.c:497)]: Calling exit handler 17398
从输出的debug日志[HAMI-core Debug(17398:140432464095040:hook.c:328)]: Hijacking nvmlDeviceGetMemoryInfo_v2来看,nvmlDeviceGetMemoryInfo_v2函数被劫持了. 使用gdb调试进入到nvmlDeviceGetMemoryInfo_v2函数,gdb调试设置参考5.6 hami-core gdb调试
(base) root@vgpu:/libvgpu/build# gdb nvidia-smi
...
(No debugging symbols found in nvidia-smi)
(gdb) b nvmlDeviceGetMemoryInfo_v2
Function "nvmlDeviceGetMemoryInfo_v2" not defined.
Make breakpoint pending on future shared library load? (y or [n]) y
Breakpoint 1 (nvmlDeviceGetMemoryInfo_v2) pending.
(gdb) r
Starting program: /usr/bin/nvidia-smi
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[HAMI-core Msg(24206:140737321068352:libvgpu.c:836)]: Initializing.....
Mon Jan 20 17:10:36 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.135 Driver Version: 550.135 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
Breakpoint 1, nvmlDeviceGetMemoryInfo_v2 (device=0x7ffff51fbf38, memory=0x7fffffffd730) at /libvgpu/src/nvml/hook.c:375
375 return _nvmlDeviceGetMemoryInfo(device,memory,2);
(gdb) info sharedlibrary
From To Syms Read Shared Object Library
0x00007ffff7fc5090 0x00007ffff7fee315 Yes /lib64/ld-linux-x86-64.so.2
0x00007ffff7f73850 0x00007ffff7fa1050 Yes ./libvgpu.so
0x00007ffff7f62040 0x00007ffff7f62105 Yes /lib/x86_64-linux-gnu/libpthread.so.0
0x00007ffff7e883a0 0x00007ffff7f038c8 Yes /lib/x86_64-linux-gnu/libm.so.6
0x00007ffff7e76040 0x00007ffff7e76105 Yes /lib/x86_64-linux-gnu/libdl.so.2
0x00007ffff7c74700 0x00007ffff7e0693d Yes /lib/x86_64-linux-gnu/libc.so.6
0x00007ffff7c46080 0x00007ffff7c46275 Yes /lib/x86_64-linux-gnu/librt.so.1
0x00007ffff6157d80 0x00007ffff662b504 Yes (*) /lib/x86_64-linux-gnu/libcuda.so.1
0x00007ffff4e18740 0x00007ffff4f6aef2 Yes (*) /lib/x86_64-linux-gnu/libnvidia-ml.so.1
(*): Shared library is missing debugging information.
(gdb) s
_nvmlDeviceGetMemoryInfo (device=0x7ffff51fbf38, memory=0x7fffffffd730, version=2) at /libvgpu/src/nvml/hook.c:319
319 nvmlReturn_t _nvmlDeviceGetMemoryInfo(nvmlDevice_t device,nvmlMemory_t* memory,int version) {
(gdb) l
nvmlReturn_t nvmlDeviceGetMemoryInfo_v2(nvmlDevice_t device, nvmlMemory_v2_t* memory) {
return _nvmlDeviceGetMemoryInfo(device,memory,2);
}
/**
* 获取设备内存信息的内部函数
* 这是一个hook函数,用于拦截和修改NVML的内存信息查询结果,实现GPU内存使用的限制和监控
*/
nvmlReturn_t _nvmlDeviceGetMemoryInfo(nvmlDevice_t device, nvmlMemory_t* memory, int version) {
// 用于存储设备ID的变量
unsigned int dev_id;
// 记录函数入口的调试日志
LOG_DEBUG("into nvmlDeviceGetMemoryInfo");
// 根据API版本调用相应的原始NVML函数获取基础内存信息
// 这一步会获取GPU的原始内存信息,后续可能会根据限制进行修改
switch (version) {
case 1:
// v1版本API调用,直接使用nvmlMemory_t结构体
// NVML_OVERRIDE_CALL宏用于调用原始的NVML库函数
CHECK_NVML_API(NVML_OVERRIDE_CALL(nvml_library_entry, nvmlDeviceGetMemoryInfo, device, memory));
break;
case 2:
// v2版本API调用,需要将memory指针转换为nvmlMemory_v2_t*类型
// nvmlMemory_v2_t结构体包含了更多的内存相关信息
CHECK_NVML_API(NVML_OVERRIDE_CALL(nvml_library_entry, nvmlDeviceGetMemoryInfo_v2, device, (nvmlMemory_v2_t *)memory));
}
// 记录从NVML获取的原始内存信息,用于调试和比较
LOG_DEBUG("origin_free=%lld total=%lld\n", memory->free, memory->total);
// 获取NVML设备索引,并转换为CUDA设备索引
// NVML和CUDA的设备索引可能不同,需要进行映射
CHECK_NVML_API(nvmlDeviceGetIndex(device, &dev_id));
int cudadev = nvml_to_cuda_map(dev_id);
if (cudadev < 0) {
// 设备映射失败,说明找不到对应的CUDA设备
// 此时返回原始的NVML信息,不做修改
return NVML_SUCCESS;
}
// 获取当前设备的实际内存使用情况和限制
// 这些信息来自我们自己的内存跟踪系统,而不是NVML
size_t usage = get_current_device_memory_usage(cudadev); // 获取当前实际使用的GPU内存量
size_t monitor = get_current_device_memory_monitor(cudadev); // 获取内存监控的阈值设置
// 从共享内存region中获取limit,跟上面的do_init_device_memory_limits函数有关
size_t limit = get_current_device_memory_limit(cudadev); // 获取设置的内存使用上限
// 记录实际的内存使用情况,用于调试
LOG_DEBUG("usage=%ld limit=%ld monitor=%ld", usage, limit, monitor);
// 检查传入的memory指针是否为空
// 这是一个安全检查,防止访问空指针
if (memory == NULL) {
return NVML_SUCCESS;
}
// 根据是否设置了内存限制来更新返回的内存信息
if (limit == 0) {
// 未设置内存限制的情况(limit = 0)
// 此时只更新已用内存信息,保持其他信息(如total)不变
switch (version) {
case 1:
// 更新v1版本结构体中的已用内存字段
memory->used = usage;
return NVML_SUCCESS;
case 2:
// 更新v2版本结构体中的已用内存字段
((nvmlMemory_v2_t *)memory)->used = usage;
return NVML_SUCCESS;
}
} else {
// 设置了内存限制的情况
// 需要更新所有内存相关字段,包括total、free和used
switch (version) {
case 1:
// 更新v1版本结构体的所有字段
memory->free = (limit - usage); // 可用内存为限制值减去已用内存
memory->total = limit; // 将总内存设置为限制值
memory->used = usage; // 设置已用内存
return NVML_SUCCESS;
case 2:
// 更新v2版本结构体的所有字段
((nvmlMemory_v2_t *)memory)->used = usage; // 设置已用内存
((nvmlMemory_v2_t *)memory)->total = limit; // 将总内存设置为限制值
((nvmlMemory_v2_t *)memory)->used = usage; // BUG: 这行是重复的,应该删除
// 可能是复制粘贴导致的错误
return NVML_SUCCESS;
}
}
// 所有情况都已在switch语句中返回
// 这个return语句实际上永远不会被执行到
return NVML_SUCCESS;
}
CUDA_DEVICE_SM_LIMIT=50,是如何控制GPU利用率稳定在50%的,有个监控在watcher吗?通过源码查看,大概率就是这个文件了HAMi-core/src/multiprocess/multiprocess_utilization_watcher.c
cuInit -> postInit -> init_utilization_watcher -> utilization_watcher
在cuInit初始化驱动API的时候,被hook劫持,最后会调用到utilization_watcher函数,这个函数会持续监控GPU利用率,并根据设置的CUDA_DEVICE_SM_LIMIT来调整GPU利用率。
监控线程函数
void* utilization_watcher() {
nvmlInit(); // 初始化NVIDIA管理库
int userutil[CUDA_DEVICE_MAX_COUNT]; // 存储每个设备的用户使用率
int sysprocnum; // 系统进程数
int share = 0; // 当前分配的share值
int upper_limit = get_current_device_sm_limit(0); // 获取SM使用率上限
LOG_DEBUG("upper_limit=%d\n",upper_limit);
// 持续监控循环
while (1) {
nanosleep(&g_wait, NULL); // 周期性休眠
// 确保目标进程存在
if (pidfound==0) {
update_host_pid(); // 更新主机进程ID
if (pidfound==0)
continue;
}
// 初始化GPU设备SM使用率
init_gpu_device_sm_utilization();
// 获取当前GPU使用情况
get_used_gpu_utilization(userutil,&sysprocnum);
// 动态扩容机制
// 当share达到最大值且没有可用核心时,翻倍总容量
if ((share==g_total_cuda_cores) && (g_cur_cuda_cores<0)) {
g_total_cuda_cores *= 2;
share = g_total_cuda_cores;
}
// 计算新的share值
share = delta(upper_limit, userutil[0], share);
LOG_DEBUG("userutil=%d currentcores=%d total=%d limit=%d share=%d\n",
userutil[0],g_cur_cuda_cores,g_total_cuda_cores,upper_limit,share);
// 更新令牌数
change_token(share);
}
}
这个GPU SM(Stream Multiprocessor)资源的动态分配和限制机制其实是基于令牌桶思想. 接下来来看下GPU利用率令牌桶的实现:
- 关键全局变量
static int g_sm_num; // GPU中的Stream Multiprocessor数量
static int g_max_thread_per_sm; // 每个SM支持的最大线程数
static volatile int g_cur_cuda_cores; // 当前可用的CUDA核心数(令牌数)
static volatile int g_total_cuda_cores; // 总的CUDA核心数(桶容量)
extern int pidfound; // 是否找到目标进程的标志
int cuda_to_nvml_map[16]; // CUDA设备到NVML设备的映射关系
- 令牌消耗函数
void rate_limiter(int grids, int blocks) {
int before_cuda_cores = 0; // 消耗令牌前的数量
int after_cuda_cores = 0; // 消耗令牌后的数量
int kernel_size = grids; // 将要启动的kernel大小(需要消耗的令牌数)
// 等待直到有最近的kernel信息
while (get_recent_kernel()<0) {
sleep(1); // 如果没有最近的kernel信息,睡眠1秒后重试
}
set_recent_kernel(2); // 设置kernel状态为2
// 检查是否需要进行限制
// 如果SM利用率限制>=100%或为0,表示不需要限制
if ((get_current_device_sm_limit(0)>=100) || (get_current_device_sm_limit(0)==0))
return;
// 如果利用率开关未打开,也不需要限制
if (get_utilization_switch()==0)
return;
LOG_DEBUG("grid: %d, blocks: %d", grids, blocks);
LOG_DEBUG("launch kernel %d, curr core: %d", kernel_size, g_cur_cuda_cores);
// 循环尝试消耗令牌
do {
CHECK:
before_cuda_cores = g_cur_cuda_cores; // 获取当前可用令牌数
LOG_DEBUG("current core: %d", g_cur_cuda_cores);
// 如果没有足够的令牌,等待一段时间后重试
if (before_cuda_cores < 0) {
nanosleep(&g_cycle, NULL); // 使用nanosleep避免忙等待
goto CHECK;
}
// 计算消耗令牌后的数量
after_cuda_cores = before_cuda_cores - kernel_size;
// CAS操作确保原子性,如果失败则重试整个过程
} while (!CAS(&g_cur_cuda_cores, before_cuda_cores, after_cuda_cores));
}
rate_limiter在hook的cuLaunchKernel中被调用,拦截了原始的cuLaunchKernel调用,在原始调用前后添加了资源控制逻辑,保持了与原始CUDA API相同的接口. 什么时候会触发cuLaunchKernel?大多数CUDA计算最终都会转化为kernel的执行,而cuLaunchKernel是启动kernel的底层API.
- 令牌更新函数
static void change_token(int delta) {
int cuda_cores_before = 0; // 更新前的令牌数
int cuda_cores_after = 0; // 更新后的令牌数
LOG_DEBUG("delta: %d, curr: %d", delta, g_cur_cuda_cores);
// 循环尝试更新令牌数
do {
cuda_cores_before = g_cur_cuda_cores; // 获取当前令牌数
cuda_cores_after = cuda_cores_before + delta; // 计算新的令牌数
// 确保不超过最大容量
if (cuda_cores_after > g_total_cuda_cores) {
cuda_cores_after = g_total_cuda_cores;
}
// CAS操作确保原子性,如果失败则重试
} while (!CAS(&g_cur_cuda_cores, cuda_cores_before, cuda_cores_after));
}
- 令牌计算函数
int delta(int up_limit, int user_current, int share) {
// 计算实际使用率与限制之间的差异
// 如果差异小于5%,则使用5%作为最小调整单位
int utilization_diff =
abs(up_limit - user_current) < 5 ? 5 : abs(up_limit - user_current);
// 计算基础增量
// 公式: (SM数量)² * 每个SM的最大线程数 * 使用率差异 / 2560
// 2560是一个经验值,用于将增量控制在合理范围
int increment =
g_sm_num * g_sm_num * g_max_thread_per_sm * utilization_diff / 2560;
// 当使用率差异大于限制的一半时,加速调整
// 这是为了在使用率变化剧烈时能快速响应
if (utilization_diff > up_limit / 2) {
increment = increment * utilization_diff * 2 / (up_limit + 1);
}
// 根据当前使用率调整share值
if (user_current <= up_limit) {
// 使用率低于限制时,增加share
// 但确保不超过总容量
share = share + increment > g_total_cuda_cores ?
g_total_cuda_cores : share + increment;
} else {
// 使用率高于限制时,减少share
// 但确保不小于0
share = share - increment < 0 ? 0 : share - increment;
}
return share;
}
5.6 hami-core gdb调试
# 检查动态库是否包含调试符号
readelf -S libvgpu.so | grep debug
修改CMakeLists.txt编译参数, -g是生成调试信息,包括源代码行号、变量名等,可以被GDB等调试器更好地调试;-fvisibility=hidden控制共享库中符号的可见性,可以减少动态链接时的符号冲突,提高加载速度,并减小二进制大小
# Compile flags
if (CMAKE_BUILD_TYPE STREQUAL Debug)
set(LIBRARY_COMPILE_FLAGS -shared -fPIC -g -D_GNU_SOURCE -fvisibility=hidden -Wall)
set(TEST_COMPILE_FLAGS -O1 -g)
else()
......
编译时候设置-fvisibility=hidden,针对hook的函数,需要设置__attribute__((visibility("default"))),否则无法被gdb调试.所有需要批量把cuda、nvml hook的函数都设置为默认可见
// 以nvmlDeviceGetMemoryInfo函数为例,设置为默认可见
__attribute__((visibility("default")))
nvmlReturn_t nvmlDeviceGetMemoryInfo(nvmlDevice_t device, nvmlMemory_t* memory) {
return _nvmlDeviceGetMemoryInfo(device,memory,1);
}
gdb单步调试,libvgpu.so的函数被调用
(base) root@vgpu:/libvgpu/build# LD_PRELOAD=./libvgpu.so gdb test/test_alloc
GNU gdb (Ubuntu 12.1-0ubuntu1~22.04.2) 12.1
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from test/test_alloc...
(gdb) b main
Breakpoint 1 at 0x17c1: file /libvgpu/test/test_alloc.c, line 68.
(gdb) r
Starting program: /libvgpu/build/test/test_alloc
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Breakpoint 1, main () at /libvgpu/test/test_alloc.c:68
68 int main() {
(gdb) sharedlibrary libvgpu.so
Symbols already loaded for ./libvgpu.so
(gdb) b _nvmlDeviceGetMemoryInfo
Breakpoint 2 at 0x7ffff7f86075: file /libvgpu/src/nvml/hook.c, line 317.
(gdb) b /libvgpu/src/nvml/hook.c:317
Note: breakpoint 2 also set at pc 0x7ffff7f86075.
Breakpoint 3 at 0x7ffff7f86075: file /libvgpu/src/nvml/hook.c, line 317.
5.7 vGPUMonitor调试环境
远程gpu服务器上dlv启动vGPUMonitor,本地goland添加Go Remote Debugger指向:2347
KUBECONFIG=/root/.kube/config \
NODE_NAME=vgpu \
NVIDIA_VISIBLE_DEVICES=all \
NVIDIA_MIG_MONITOR_DEVICES=all \
HOOK_PATH=/usr/local/vgpu \
dlv exec bin/vGPUmonitor --headless -l 0.0.0.0:2347 --api-version=2
5.8 vGPUMonitor核心逻辑
启动函数,程序的主要功能是监控vGPU的使用情况,并提供相应的指标收集和反馈机制
func main() {
// 校验环境变量HOOK_PATH必须存在
if err := ValidateEnvVars(); err != nil {
klog.Fatalf("Failed to validate environment variables: %v", err)
}
// 创建一个容器列表器实例,用于跟踪和管理GPU容器Usage
containerLister, err := nvidia.NewContainerLister()
if err != nil {
klog.Fatalf("Failed to create container lister: %v", err)
}
cgroupDriver = 0
// 创建一个错误通道用于错误处理, 用于在不同goroutine间传递错误信息(看起来没有意义了,因为main函数里没有使用)
errchannel := make(chan error)
//go serveInfo(errchannel)
// 初始化vGPUmonitor metrics
go initMetrics(containerLister)
// 持续监控容器使用情况
go watchAndFeedback(containerLister)
// 等待错误通道传递错误信息,errchannel实际上没用到
for {
err := <-errchannel
klog.Errorf("failed to serve: %v", err)
}
}
主要使用到的结构体
// ContainerLister结构体,用于存储容器列表使用信息
type ContainerLister struct {
containerPath string
// map存储容器使用信息,key为<podUID_containerName>
containers map[string]*ContainerUsage
// 互斥锁,用于保护containers map的并发访问
mutex sync.Mutex
// k8s clientSet
clientset *kubernetes.Clientset
}
// ContainerUsage结构体,用于存储单个容器使用信息
type ContainerUsage struct {
// Pod 的唯一标识符
PodUID string
// 容器名称
ContainerName string
// 容器使用信息
data []byte
Info UsageInfo
}
// UsageInfo接口,定义了获取和设置NVIDIA GPU设备使用情况的方法
type UsageInfo interface {
// DeviceMax 返回系统中支持的最大GPU设备数量
DeviceMax() int
// DeviceNum 返回当前实际使用的GPU设备数量
DeviceNum() int
// DeviceMemoryContextSize 返回指定GPU设备的上下文内存大小
DeviceMemoryContextSize(idx int) uint64
// DeviceMemoryModuleSize 返回指定GPU设备的模块内存大小
DeviceMemoryModuleSize(idx int) uint64
// DeviceMemoryBufferSize 返回指定GPU设备的缓冲区内存大小
DeviceMemoryBufferSize(idx int) uint64
// DeviceMemoryOffset 返回指定GPU设备的内存偏移量
DeviceMemoryOffset(idx int) uint64
// DeviceMemoryTotal 返回指定GPU设备的总内存大小
DeviceMemoryTotal(idx int) uint64
// DeviceSmUtil 返回指定GPU设备的SM(Streaming Multiprocessor)利用率
DeviceSmUtil(idx int) uint64
// SetDeviceSmLimit 设置GPU设备的SM使用限制
SetDeviceSmLimit(l uint64)
// IsValidUUID 检查指定GPU设备的UUID是否有效
IsValidUUID(idx int) bool
// DeviceUUID 返回指定GPU设备的UUID
DeviceUUID(idx int) string
// DeviceMemoryLimit 返回指定GPU设备的内存使用限制
DeviceMemoryLimit(idx int) uint64
// SetDeviceMemoryLimit 设置GPU设备的内存使用限制
SetDeviceMemoryLimit(l uint64)
// LastKernelTime 返回最后一次内核执行的时间戳
LastKernelTime() int64
// UsedMemory 返回指定GPU设备的已使用内存(当前已注释)
//UsedMemory(idx int) (uint64, error)
// GetPriority 返回GPU任务的优先级
GetPriority() int
// GetRecentKernel 获取最近的内核执行状态
GetRecentKernel() int32
// SetRecentKernel 设置最近的内核执行状态
SetRecentKernel(v int32)
// GetUtilizationSwitch 获取利用率开关状态
GetUtilizationSwitch() int32
// SetUtilizationSwitch 设置利用率开关状态
SetUtilizationSwitch(v int32)
}
容器列表器实例,如何更新containers map?
func (l *ContainerLister) Update() error {
// 是否设置NODE_NAME环境变量
nodename := os.Getenv(util.NodeNameEnvName)
if nodename == "" {
return fmt.Errorf("env %s not set", util.NodeNameEnvName)
}
// 获取指定节点上的所有Pod
pods, err := l.clientset.CoreV1().Pods("").List(context.Background(), metav1.ListOptions{
FieldSelector: fmt.Sprintf("spec.nodeName=%s", nodename),
})
if err != nil {
return err
}
// 加锁,保护containers map的并发访问
l.mutex.Lock()
defer l.mutex.Unlock()
// 读取容器目录下的所有文件
entries, err := os.ReadDir(l.containerPath)
if err != nil {
return err
}
// 遍历容器目录下的所有文件
for _, entry := range entries {
if !entry.IsDir() {
continue
}
// 获取容器目录的完整路径
// containerPath: /usr/local/vgpu/containers
// entry.Name(): 305df464-2a9e-485d-9c80-f2901a9259cc_pytorch-container
dirName := filepath.Join(l.containerPath, entry.Name())
// 检查容器是否存在,如果不存在的话
if !isValidPod(entry.Name(), pods) {
// 获取容器目录的元数据
dirInfo, err := os.Stat(dirName)
// 如果容器目录存在,并且修改时间在300秒内,则跳过
if err == nil && dirInfo.ModTime().Add(time.Second*300).After(time.Now()) {
continue
}
klog.Infof("Removing dirname %s in monitorpath", dirName)
// 判断map中是否存在该容器
if c, ok := l.containers[entry.Name()]; ok {
// 如果存在,则释放内存
syscall.Munmap(c.data)
// 删除map中的该容器
delete(l.containers, entry.Name())
}
// 删除容器目录
_ = os.RemoveAll(dirName)
continue
}
// 检查容器是否存在,如果存在的话
// 判断map中是否存在该容器
if _, ok := l.containers[entry.Name()]; ok {
continue
}
// 加载容器使用信息
usage, err := loadCache(dirName)
if err != nil {
klog.Errorf("Failed to load cache: %s, error: %v", dirName, err)
continue
}
// 如果容器使用信息为空,则跳过
if usage == nil {
// no cuInit in container
continue
}
// 获取pod uid和container name
usage.PodUID = strings.Split(entry.Name(), "_")[0]
usage.ContainerName = strings.Split(entry.Name(), "_")[1]
// 将容器使用信息添加到map中
l.containers[entry.Name()] = usage
klog.Infof("Adding ctr dirname %s in monitorpath", dirName)
}
return nil
}
loadCache函数,如何加载容器使用信息?
func loadCache(fpath string) (*ContainerUsage, error) {
klog.Infof("Checking path %s", fpath)
// 读取容器目录下的所有文件,形如/usr/local/vgpu/containers/305df464-2a9e-485d-9c80-f2901a9259cc_pytorch-container/
files, err := os.ReadDir(fpath)
if err != nil {
return nil, err
}
// 检查文件数量,如果文件数量大于2,则返回错误
if len(files) > 2 {
return nil, errors.New("cache num not matched")
}
// 如果文件数量为0,则返回nil
if len(files) == 0 {
return nil, nil
}
cacheFile := ""
for _, val := range files {
// 检查文件名是否包含libvgpu.so
if strings.Contains(val.Name(), "libvgpu.so") {
continue
}
// 检查文件名是否包含.cache
if !strings.Contains(val.Name(), ".cache") {
continue
}
// 获取cache文件的完整路径
cacheFile = filepath.Join(fpath, val.Name())
break
}
// 如果cacheFile为空,则返回nil
if cacheFile == "" {
klog.Infof("No cache file in %s", fpath)
return nil, nil
}
// 获取cache文件的元数据
info, err := os.Stat(cacheFile)
if err != nil {
klog.Errorf("Failed to stat cache file: %s, error: %v", cacheFile, err)
return nil, err
}
// 检查cache文件大小,如果小于headerT结构体的大小,则返回错误
if info.Size() < int64(unsafe.Sizeof(headerT{})) {
return nil, fmt.Errorf("cache file size %d too small", info.Size())
}
// 打开cache文件
f, err := os.OpenFile(cacheFile, os.O_RDWR, 0666)
if err != nil {
klog.Errorf("Failed to open cache file: %s, error: %v", cacheFile, err)
return nil, err
}
defer func(f *os.File) {
_ = f.Close()
}(f)
usage := &ContainerUsage{}
// 将cache文件映射到内存
// - 内存映射文件
// 参数说明:
// - fd: 文件描述符
// - offset: 从文件开始处的偏移量
// - length: 要映射的字节数
// - prot: 内存保护标志 (读/写)
// - flags: 映射标志
usage.data, err = syscall.Mmap(int(f.Fd()), 0, int(info.Size()), syscall.PROT_WRITE|syscall.PROT_READ, syscall.MAP_SHARED)
if err != nil {
klog.Errorf("Failed to mmap cache file: %s, error: %v", cacheFile, err)
return nil, err
}
// 将[]byte转换为结构体指针
head := (*headerT)(unsafe.Pointer(&usage.data[0]))
// 校验initializedFlag,不清楚为什么SharedRegionMagicFlag=19920718
if head.initializedFlag != SharedRegionMagicFlag {
// 释放内存映射
_ = syscall.Munmap(usage.data)
return nil, fmt.Errorf("cache file magic flag not matched")
}
// 检查cache文件大小,为什么跟1197897比较,看起来是针对特定版本的NVIDIA GPU监控数据结构的大小
// usage.data 是通过 syscall.Mmap 映射的文件内容
// v0.CastSpec 和 v1.CastSpec 分别处理不同版本的数据格式
// 两个版本都实现了UsageInfo接口
if info.Size() == 1197897 {
usage.Info = v0.CastSpec(usage.data)
} else if head.majorVersion == 1 {
usage.Info = v1.CastSpec(usage.data)
} else {
_ = syscall.Munmap(usage.data)
return nil, fmt.Errorf("unknown cache file size %d version %d.%d", info.Size(), head.majorVersion, head.minorVersion)
}
return usage, nil
}
vGPUmonitor metrics,如何初始化?
// NewClusterManager first creates a Prometheus-ignorant ClusterManager
// instance. Then, it creates a ClusterManagerCollector for the just created
// ClusterManager. Finally, it registers the ClusterManagerCollector with a
// wrapping Registerer that adds the zone as a label. In this way, the metrics
// collected by different ClusterManagerCollectors do not collide.
func NewClusterManager(zone string, reg prometheus.Registerer, containerLister *nvidia.ContainerLister) *ClusterManager {
// 创建一个ClusterManager实例
c := &ClusterManager{
Zone: zone,
containerLister: containerLister,
}
// 创建一个PodLister实例,用于获取Pod信息
informerFactory := informers.NewSharedInformerFactoryWithOptions(containerLister.Clientset(), time.Hour*1)
c.PodLister = informerFactory.Core().V1().Pods().Lister()
stopCh := make(chan struct{})
// 启动informerFactory,用于获取Pod信息
informerFactory.Start(stopCh)
// 创建一个ClusterManagerCollector实例,用于收集metrics
cc := ClusterManagerCollector{ClusterManager: c}
// 将ClusterManagerCollector实例注册到prometheus
prometheus.WrapRegistererWith(prometheus.Labels{"zone": zone}, reg).MustRegister(cc)
return c
}
如何持续监控容器使用情况?
func watchAndFeedback(lister *nvidia.ContainerLister) {
// 初始化 NVIDIA Management Library
nvml.Init()
// 无限循环,持续监控
for {
// 每5秒执行一次
time.Sleep(time.Second * 5)
// 更新容器列表器实例的containers map
err := lister.Update()
if err != nil {
// 如果更新失败,记录错误并继续下一次循环
klog.Errorf("Failed to update container list: %v", err)
continue
}
// 观察并处理容器状态
Observe(lister)
}
}
// Observe 监控和管理容器的 GPU 使用状态
func Observe(lister *nvidia.ContainerLister) {
// 初始化设备利用率开关映射,key是GPU UUID,value是每个优先级的使用计数
utSwitchOn := map[string]UtilizationPerDevice{}
// 获取containers map
containers := lister.ListContainers()
// 第一次遍历:统计每个 GPU 设备的使用情况
for _, c := range containers {
// 获取容器的最近内核使用计数
recentKernel := c.Info.GetRecentKernel()
if recentKernel > 0 {
// 递减内核使用计数
recentKernel--
if recentKernel > 0 {
// 遍历容器使用的所有 GPU 设备
for i := 0; i < c.Info.DeviceMax(); i++ {
// 跳过无效的 GPU UUID
if !c.Info.IsValidUUID(i) {
continue
}
// 获取 GPU 的 UUID
uuid := c.Info.DeviceUUID(i)
// 如果是新设备,初始化优先级计数数组 [0, 0]
if len(utSwitchOn[uuid]) == 0 {
utSwitchOn[uuid] = []int{0, 0}
}
// 增加对应优先级的使用计数
utSwitchOn[uuid][c.Info.GetPriority()]++
}
}
// 更新容器的内核使用计数
c.Info.SetRecentKernel(recentKernel)
}
}
// 第二次遍历:根据统计结果更新容器状态
for idx, c := range containers {
priority := c.Info.GetPriority()
recentKernel := c.Info.GetRecentKernel()
utilizationSwitch := c.Info.GetUtilizationSwitch()
// 检查是否需要阻塞(有更高优先级的任务在使用)
if CheckBlocking(utSwitchOn, priority, c) {
if recentKernel >= 0 {
klog.Infof("utSwitchon=%v", utSwitchOn)
klog.Infof("Setting Blocking to on %v", idx)
// 设置阻塞状态
c.Info.SetRecentKernel(-1)
}
} else {
if recentKernel < 0 {
klog.Infof("utSwitchon=%v", utSwitchOn)
klog.Infof("Setting Blocking to off %v", idx)
// 解除阻塞状态
c.Info.SetRecentKernel(0)
}
}
// 检查优先级冲突(同优先级是否有多个任务)
if CheckPriority(utSwitchOn, priority, c) {
if utilizationSwitch != 1 {
klog.Infof("utSwitchon=%v", utSwitchOn)
klog.Infof("Setting UtilizationSwitch to on %v", idx)
// 开启利用率限制
c.Info.SetUtilizationSwitch(1)
}
} else {
if utilizationSwitch != 0 {
klog.Infof("utSwitchon=%v", utSwitchOn)
klog.Infof("Setting UtilizationSwitch to off %v", idx)
// 关闭利用率限制
c.Info.SetUtilizationSwitch(0)
}
}
}
}
这个函数实现了一个优先级基础的 GPU 资源管理机制:
- 统计每个 GPU 设备上不同优先级任务的数量
- 根据优先级规则决定是否阻塞低优先级任务
- 处理同优先级任务的资源竞争
- 通过日志记录状态变化
这种机制可以确保:
- 高优先级任务优先获得GPU资源
- 同优先级任务公平共享GPU资源
- 低优先级任务在资源充足时才能运行
参考链接
- HAMi官方部署文档
- Nvidia Container Toolkit
- GPU 环境搭建指南:如何在裸机、Docker、K8s 等环境中使用 GPU
- GPU 环境搭建指南:使用 GPU Operator 加速 Kubernetes GPU 环境搭建
- Kubernetes教程(二一)—自定义资源支持:K8s Device Plugin 从原理到实现
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
