AI Agent核心思想 - LLM提示推理策略
ReAct提示工程
ReAct提示工程是一种用于提升大型语言模型(LLMs)性能的先进技术,它模仿人类在现实世界中的思考和行动方式。这种方法通过结合口头推理和实际行动来获取信息,从而提高模型在处理复杂任务时的准确性和可靠性。ReAct的核心思想是让LLM在执行任务时,不仅展示其内部的推理过程(即"思考"),还要模拟实际的"行动",比如搜索信息或与环境互动,以此来增强其解决问题的能力
Reflection/Self-Critique
Reflection(自我反思)是一种在人工智能领域中用于增强大型语言模型(LLMs)性能的技术。它通过模拟人类的自我反思过程,使得模型能够在执行任务时更加深入地理解问题,并生成更加准确和连贯的输出。这一概念源自于Shinn et al. (2023)的研究,他们提出了一种将策略参数化为智能体的记忆编码与LLM的参数选择配对的方法.
通过自我反思,大型语言模型不仅能够生成响应,还能够在生成的过程中模拟人类的思考过程,从而提高输出的质量和可靠性。这种方法特别适用于需要模型进行深度思考和创新的场景,如编写代码、生成新知识或解决复杂问题等。通过自我反思,模型能够更好地理解任务需求,避免常见的错误,并提高其解决问题的能力。
AI Agent框架
热门AI Agent开发框架对比:
| 框架名称 | 简介 | License | GitHub Stars | 所属公司/组织 | 开发语言 | 社区活跃度 | Github链接 |
|---|---|---|---|---|---|---|---|
| AutoGPT | 基于GPT 3.5/4的自动化生成框架,能够独立完成多目标复杂任务 | MIT | 160k | 个人Significant Gravitas | JS/Python | discord 52132名成员加入 | https://github.com/Significant-Gravitas/AutoGPT |
| AutoGen | 微软开源的多智能体应用开发框架,支持LLM工作流构建 | CC-BY-4.0, MIT | 23.5k | 微软 | Python | discord 15561名成员 | https://github.com/microsoft/autogen |
| MetaGPT | 中国团队开发的多智能体框架,应用于软件开发等场景 | MIT | 37.5k | DeepWisdom | Python | discord 4404名成员 | https://github.com/geekan/MetaGPT |
| AgentGPT | 任务驱动的自主AI代理,在浏览器配置,有依赖langchain | GPL-3.0 | 29.3k | Reworkd AI | TS/Python | discord 25419名成员 | https://github.com/reworkd/AgentGPT |
| ChatDev | 通过各种不同角色的智能体运营,包括执行官,产品官,技术官,程序员 ,审查员,测试员,设计师等 | Apache-2.0 | 21.4k | 面壁智能 | Python | discord 1589名成员 | https://github.com/OpenBMB/ChatDev |
| crewAI | 适用本地大模型AI自动化协作框架,基于langchain之上 | MIT | 10.6k | OpenAI开发 | Python | discord 4332名成员 | https://github.com/joaomdmoura/crewAI |
| LangChain | 专注于通用NLP任务的框架,支持与外部知识库的集成 | MIT | 80.2k | LangChain | Python | discord 39654名成员 | https://github.com/langchain-ai/langchain |
AutoGPT
基于GPT 3.5/4的自动化生成框架,能够独立完成多目标复杂任务
QuickStart
按照官方提供的QuickStart指引快速在本地起个demo:https://github.com/Significant-Gravitas/AutoGPT/blob/master/QUICKSTART.md
如果遇到poetry软链接不支持问题,需要改下setup.sh脚本中安装poetry的部分. poetry是不会负责Python版本的管理.
# vim setup.sh
curl -sSL https://install.python-poetry.org | sed 's/symlinks=False/symlinks=True/' | python3 -
AutoGPT官方不支持对接本地大模型,github有个讨论支持本地大模型的issue:https://github.com/Significant-Gravitas/AutoGPT/issues/25,项目维护者在帖子上答复即将实现这个功能。
核心组件
- Agent:理解为开发一个叫AutoGPT的Agent
- Benchmark:提供
agbenchmark工具对开发的agent进行测试评分 - Forge:提供一些现成的模版用于Agent开发
- Frontend:简易使用、开源的前端UI,适用于任何兼容Agent协议的Agent
Agent协议:用于统一agents开发的一套准则,来自AI-Engineer-Foundation提出的Agent Protocol,AutoGPT就是采用Agent protocol来开发Agent.
AutoGPT在构建agent的生态,包括benchmark和protocol
部署
提前设置好.condarc,用命令conda config --show-sources校验
# vim ~/.condarc
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
show_channel_urls: true
ssl_verify: false
1.使用conda创建一个虚拟环境
conda create --name autogpt python=3.10
conda activate autogpt
2.安装poetry
pip3 install poetry
3.克隆autogpt仓库
git clone https://github.com/Significant-Gravitas/AutoGPT.git
cd autogpts/autogpt
4.配置环境变量
cp .env.template .env
vim .env
OPENAI_API_KEY=sk-qwertykeys123456 # 替换为实际的API KEY
5.安装依赖
poetry install
6.运行AutoGPT,提供两种交互方式,一种是过时的命令行方式;另一种是Agent协议模式下的webUI方式。
# 命令行方式
./autogpt.sh run
# webUI方式
./autogpt.sh serve
默认输出产出在./data/agents目录下
测试验证
例如提个任务:使用golang编写监控虚拟机磁盘的功能
(autogpt) iceyao$ ./autogpt.sh run
Missing packages:
auto-gpt-plugin-template (*) @ git+https://github.com/Significant-Gravitas/Auto-GPT-Plugin-Template@0.1.0, autogpt-forge (*) @ git+https://github.com/Significant-Gravitas/AutoGPT.git@ab05b7ae70754c063909#subdirectory=autogpts/forge, beautifulsoup4 (>=4.12.2,<5.0.0), boto3 (>=1.33.6,<2.0.0), colorama (>=0.4.6,<0.5.0), demjson3 (>=3.0.0,<4.0.0), distro (>=1.8.0,<2.0.0), docker, duckduckgo-search (>=5.0.0,<6.0.0), en-core-web-sm (*) @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.5.0/en_core_web_sm-3.5.0-py3-none-any.whl, fastapi (>=0.109.1,<0.110.0), ftfy (>=6.1.1,<7.0.0), gitpython (>=3.1.32,<4.0.0), google-api-python-client, gTTS (>=2.3.1,<3.0.0), hypercorn (>=0.14.4,<0.15.0), inflection, jsonschema, numpy, openai (>=1.7.2,<2.0.0), orjson (>=3.8.10,<4.0.0), Pillow, pinecone-client (>=2.2.1,<3.0.0), playsound (>=1.2.2,<1.3.0), pydantic, pylatexenc, pypdf (>=3.1.0,<4.0.0), python-docx, python-dotenv (>=1.0.0,<2.0.0), pyyaml (>=6.0,<7.0), readability-lxml (>=0.8.1,<0.9.0), redis, selenium (>=4.11.2,<5.0.0), sentry-sdk (>=1.40.4,<2.0.0), spacy (>=3.0.0,<4.0.0), tenacity (>=8.2.2,<9.0.0), tiktoken (>=0.5.0,<0.6.0), webdriver-manager, openapi-python-client (>=0.14.0,<0.15.0), google-cloud-logging (>=3.8.0,<4.0.0), google-cloud-storage (>=2.13.0,<3.0.0), psycopg2-binary (>=2.9.9,<3.0.0)
Installing dependencies from lock file
No dependencies to install or update
Installing the current project: agpt (0.5.0)
Finished installing packages! Starting AutoGPT...
2024-04-07 14:53:42,144 INFO HTTP Request: GET https://api.openai.com/v1/models "HTTP/1.1 200 OK"
2024-04-07 14:53:42,865 INFO NEWS: Welcome to AutoGPT!
2024-04-07 14:53:42,866 INFO NEWS: Below you'll find the latest AutoGPT News and feature updates!
2024-04-07 14:53:42,866 INFO NEWS: If you don't wish to see this message, you can run AutoGPT with the --skip-news flag.
2024-04-07 14:53:42,867 INFO NEWS:
2024-04-07 14:53:42,867 INFO NEWS: QUICK LINKS 🔗
2024-04-07 14:53:42,867 INFO NEWS: --------------
2024-04-07 14:53:42,867 INFO NEWS: 🌎 Official Website: https://agpt.co.
2024-04-07 14:53:42,868 INFO NEWS: 📖 User Guide: https://docs.agpt.co/autogpt.
2024-04-07 14:53:42,868 INFO NEWS: 👩 Contributors Wiki: https://github.com/Significant-Gravitas/Nexus/wiki/Contributing.
2024-04-07 14:53:42,868 INFO NEWS:
2024-04-07 14:53:42,868 INFO NEWS: v0.5.0 RELEASE HIGHLIGHTS! 🚀🚀
2024-04-07 14:53:42,868 INFO NEWS: -------------------------------
2024-04-07 14:53:42,869 INFO NEWS: Cloud-readiness, a new UI, support for the newest Agent Protocol version, and much more:
2024-04-07 14:53:42,869 INFO NEWS: v0.5.0 is our biggest release yet!
2024-04-07 14:53:42,869 INFO NEWS:
2024-04-07 14:53:42,869 INFO NEWS: Take a look at the Release Notes on Github for the full changelog:
2024-04-07 14:53:42,869 INFO NEWS: https://github.com/Significant-Gravitas/AutoGPT/releases.
2024-04-07 14:53:42,870 INFO NEWS:
2024-04-07 14:53:42,871 INFO Smart LLM: gpt-4-turbo-preview
2024-04-07 14:53:42,872 INFO Fast LLM: gpt-3.5-turbo-0125
2024-04-07 14:53:42,872 INFO Browser: chrome
2024-04-07 14:53:42,874 INFO Code Execution: DISABLED (Docker unavailable)
Enter the task that you want AutoGPT to execute, with as much detail as possible: Enter the task that you want AutoGPT to execute, with as much detail as possible: 编
Enter the task that you want AutoGPT to execute, with as much detail as possible: 使用golang编写监控虚拟机磁盘的功能
2024-04-07 14:54:34,471 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:54:34,479 INFO Current AI Settings:
2024-04-07 14:54:34,480 INFO -------------------:
2024-04-07 14:54:34,480 INFO Name : GoVMDiskMonitorGPT
2024-04-07 14:54:34,480 INFO Role : a specialized agent designed to monitor virtual machine disk usage using Go programming, ensuring efficient disk space management and preventing potential storage issues.
2024-04-07 14:54:34,480 INFO Constraints:
2024-04-07 14:54:34,480 INFO - Exclusively use the commands listed below.
2024-04-07 14:54:34,480 INFO - You can only act proactively, and are unable to start background jobs or set up webhooks for yourself. Take this into account when planning your actions.
2024-04-07 14:54:34,481 INFO - You are unable to interact with physical objects. If this is absolutely necessary to fulfill a task or objective or to complete a step, you must ask the user to do it for you. If the user refuses this, and there is no other way to achieve your goals, you must terminate to avoid wasting time and energy.
2024-04-07 14:54:34,481 INFO - Do not access or modify user data stored on the virtual machine disks without explicit permission.
2024-04-07 14:54:34,481 INFO - Ensure the monitoring tool respects the privacy and security settings of the virtual machines it is monitoring.
2024-04-07 14:54:34,481 INFO - Limit the impact on virtual machine performance by optimizing the monitoring tool's resource usage.
2024-04-07 14:54:34,504 INFO - Do not store sensitive information in plaintext within the application code or logs.
2024-04-07 14:54:34,505 INFO - Ensure compliance with relevant data protection and privacy laws.
2024-04-07 14:54:34,505 INFO Resources:
2024-04-07 14:54:34,505 INFO - Internet access for searches and information gathering.
2024-04-07 14:54:34,505 INFO - The ability to read and write files.
2024-04-07 14:54:34,505 INFO - You are a Large Language Model, trained on millions of pages of text, including a lot of factual knowledge. Make use of this factual knowledge to avoid unnecessary gathering of information.
2024-04-07 14:54:34,505 INFO Best practices:
2024-04-07 14:54:34,506 INFO - Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2024-04-07 14:54:34,506 INFO - Constructively self-criticize your big-picture behavior constantly.
2024-04-07 14:54:34,506 INFO - Reflect on past decisions and strategies to refine your approach.
2024-04-07 14:54:34,506 INFO - Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
2024-04-07 14:54:34,506 INFO - Only make use of your information gathering abilities to find information that you don't yet have knowledge of.
2024-04-07 14:54:34,506 INFO - Periodically check the disk usage on virtual machines to identify potential storage issues before they become critical.
2024-04-07 14:54:34,506 INFO - Implement logging mechanisms to keep a historical record of disk space usage trends over time.
2024-04-07 14:54:34,507 INFO - Use Go's concurrency features to monitor multiple virtual machines efficiently.
2024-04-07 14:54:34,507 INFO - Notify administrators via email or another preferred communication channel when disk space usage exceeds a predefined threshold.
2024-04-07 14:54:34,507 INFO - Provide clear documentation and comments within the code to ensure easy maintenance and scalability.
Continue with these settings? [Y/n] 2024-04-07 14:54:34,757 INFO NOTE: All files/directories created by this agent can be found inside its workspace at: /Users/iceyao/Desktop/AutoGPT/autogpts/autogpt/data/agents/GoVMDiskMonitorGPT-07d8f7e6/workspace
| Thinking...
2024-04-07 14:54:43,379 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:54:43,761 INFO GOVMDISKMONITORGPT THOUGHTS: The initial step in developing this feature is to understand the requirements and the environment in which the monitoring tool will operate.
2024-04-07 14:54:43,762 INFO REASONING: Developing such a tool requires knowledge of the APIs or libraries available in Go for accessing disk usage information. Given the constraints, I must use my base knowledge without executing code or directly accessing Go libraries.
2024-04-07 14:54:43,762 INFO PLAN:
2024-04-07 14:54:43,762 INFO - Ask the user for details regarding the virtual machine environment and operating systems.
2024-04-07 14:54:43,763 INFO - Research Go libraries or standard library packages that could be used for disk monitoring.
2024-04-07 14:54:43,763 INFO - Structure a basic outline of the monitoring tool, including key functions and concurrency.
2024-04-07 14:54:43,763 INFO - Consider how to respect privacy and optimize performance in the tool's design.
2024-04-07 14:54:43,763 INFO - Plan for user notifications and logging of disk usage trends.
2024-04-07 14:54:43,764 INFO CRITICISM: I immediately considered technical details without first clarifying the scope of the virtual machine environment (e.g., VMWare, VirtualBox) and the specific operating system(s) the virtual machines will be running. This information could impact the approach and available libraries.
2024-04-07 14:54:43,764 INFO SPEAK: Could you please specify the virtual machine environment (e.g., VMWare, VirtualBox) and the operating systems of the virtual machines that you are using?
2024-04-07 14:54:43,764 INFO NEXT ACTION: COMMAND = ask_user ARGUMENTS = {'question': 'Could you please specify the virtual machine environment (e.g., VMWare, VirtualBox) and the operating systems of the virtual machines that you are using?'}
2024-04-07 14:54:43,764 INFO Enter 'y' to authorise command, 'y -N' to run N continuous commands, 'n' to exit program, or enter feedback for GoVMDiskMonitorGPT...
Input: 2024-04-07 14:54:43,765 WARNING Invalid input format.
Input: y
2024-04-07 14:54:51,006 INFO -=-=-=-=-=-=-= COMMAND AUTHORISED BY USER -=-=-=-=-=-=-=
Q: Could you please specify the virtual machine environment (e.g., VMWare, VirtualBox) and the operating systems of the virtual machines that you are using?
A:
2024-04-07 14:55:35,296 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:55:35,300 INFO SYSTEM: The user's answer: ''
2024-04-07 14:55:56,976 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:55:56,993 INFO GOVMDISKMONITORGPT THOUGHTS: Without specific details on the virtual machine environment and operating system, the strategy must be adjusted to provide a more generalized approach to monitoring disk space using Go. Assuming a common scenario, the monitoring tool will need to be adaptable to various environments potentially including both Windows and Linux systems.
2024-04-07 14:55:56,994 INFO REASONING: The versatility of Go allows for the creation of cross-platform tools. System calls or external tools like `df` on Unix systems can be invoked to gather disk usage metrics. For Windows, Go's `syscall` package can be leveraged. Given the constraints, detailed operating system-specific strategies can't be designed, but guidelines can be provided.
2024-04-07 14:55:56,994 INFO PLAN:
2024-04-07 14:55:56,994 INFO - Propose a generalized approach for a Go-based disk monitoring tool.
2024-04-07 14:55:56,995 INFO - Include considerations for both Windows and Linux environments.
2024-04-07 14:55:56,995 INFO - Suggest improvements and user actions for a more tailored approach if further information is provided.
2024-04-07 14:55:56,995 INFO CRITICISM: Failing to solicit the needed information from the user limited the ability to tailor the monitoring tool's design to their specific environment. Without this information, the proposed solution might not fully meet their needs.
2024-04-07 14:55:56,996 INFO SPEAK: I'll share a basic strategy for setting up a disk space monitoring tool in Go that could be adapted to various environments. If you can provide more specific details on your virtual machine setup later, the strategy could be more precisely tailored to your needs.
2024-04-07 14:55:56,996 INFO NEXT ACTION: COMMAND = write_to_file ARGUMENTS = {'filename': 'disk_monitoring_strategy.md', 'contents': "# Disk Space Monitoring Tool Strategy in Go\n\nThis document outlines a basic strategy for implementing a disk space monitoring tool in Go, adaptable to multiple environments including both Windows and Linux systems.\n\n## General Strategy\n\n- Use Go's `os` and `syscall` packages to interact with the operating system and retrieve disk space usage.\n- For Linux environments, consider invoking external commands like `df` using Go's `os/exec` package to get disk usage information.\n- For Windows, leverage the `syscall` package to access system calls related to disk space information.\n\n## Key Considerations\n\n- Implement error handling to address the potential failures of external commands or system calls.\n- Ensure the monitoring tool can run across different operating systems by abstracting OS-specific functionality.\n- Optimize the tool's performance to minimize its impact on system resources.\n- Enhance the tool with logging capabilities for tracking disk usage over time and alerting when thresholds are exceeded.\n\nFurther refinement could be achieved with more specific details on the virtual machine environment and operating systems in use. The user is encouraged to provide this information for a more tailored approach."}
2024-04-07 14:55:56,996 INFO Enter 'y' to authorise command, 'y -N' to run N continuous commands, 'n' to exit program, or enter feedback for GoVMDiskMonitorGPT...
Input: y
2024-04-07 14:56:04,972 INFO -=-=-=-=-=-=-= COMMAND AUTHORISED BY USER -=-=-=-=-=-=-=
2024-04-07 14:56:04,972 WARNING write_to_file(filename='disk_monitoring_strategy.md', contents="# Disk Space Monitoring Tool Strategy in Go\n\nThis document outlines a basic strategy for implementing a disk space monitoring tool in Go, adaptable to multiple environments including both Windows and Linux systems.\n\n## General Strategy\n\n- Use Go's `os` and `syscall` packages to interact with the operating system and retrieve disk space usage.\n- For Linux environments, consider invoking external commands like `df` using Go's `os/exec` package to get disk usage information.\n- For Windows, leverage the `syscall` package to access system calls related to disk space information.\n\n## Key Considerations\n\n- Implement error handling to address the potential failures of external commands or system calls.\n- Ensure the monitoring tool can run across different operating systems by abstracting OS-specific functionality.\n- Optimize the tool's performance to minimize its impact on system resources.\n- Enhance the tool with logging capabilities for tracking disk usage over time and alerting when thresholds are exceeded.\n\nFurther refinement could be achieved with more specific details on the virtual machine environment and operating systems in use. The user is encouraged to provide this information for a more tailored approach.") raised an error: Cannot execute command 'write_to_file': unknown command.
2024-04-07 14:56:06,836 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:56:06,839 WARNING Command write_to_file returned an error: UnknownCommandError("Cannot execute command 'write_to_file': unknown command.")
2024-04-07 14:56:21,687 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:56:21,723 INFO GOVMDISKMONITORGPT THOUGHTS: I aimed to provide a general documentation strategy for disk monitoring without specific user input on the environment, which led to an aborted attempt due to command choice error.
2024-04-07 14:56:21,724 INFO REASONING: Given my intention was to document a general strategy, and the 'write_file' command is what I should have used instead of 'write_to_file'. There appears to have been a misunderstanding or mistake in command selection.
2024-04-07 14:56:21,724 INFO PLAN:
2024-04-07 14:56:21,724 INFO - Review and use the correct command from the provided list.
2024-04-07 14:56:21,725 INFO - Perform an action that advances towards the goal, taking into account the mistake and correcting course.
2024-04-07 14:56:21,725 INFO - Consider using 'write_file' correctly to achieve the documentation strategy output.
2024-04-07 14:56:21,725 INFO CRITICISM: I erred in choosing the correct command, highlighting a lapse in paying close attention to the provided commands. This mistake could have been avoided by more meticulously reviewing the command list.
2024-04-07 14:56:21,725 INFO SPEAK: I encountered an issue with the command used. Let me correct this and proceed with our strategy documentation.
2024-04-07 14:56:21,726 INFO NEXT ACTION: COMMAND = write_file ARGUMENTS = {'filename': 'disk_monitoring_strategy.md', 'contents': "# Disk Space Monitoring Tool Strategy in Go\n\nThis document outlines a basic strategy for implementing a disk space monitoring tool in Go, adaptable to multiple environments including both Windows and Linux systems.\n\n## General Strategy\n\n- Use Go's `os` and `syscall` packages to interact with the operating system and retrieve disk space usage.\n- For Linux environments, consider invoking external commands like `df` using Go's `os/exec` package to get disk usage information.\n- For Windows, leverage the `syscall` package to access system calls related to disk space information.\n\n## Key Considerations\n\n- Implement error handling to address the potential failures of external commands or system calls.\n- Ensure the monitoring tool can run across different operating systems by abstracting OS-specific functionality.\n- Optimize the tool's performance to minimize its impact on system resources.\n- Enhance the tool with logging capabilities for tracking disk usage over time and alerting when thresholds are exceeded.\n\nFurther refinement could be achieved with more specific details on the virtual machine environment and operating systems in use. The user is encouraged to provide this information for a more tailored approach."}
2024-04-07 14:56:21,772 INFO Enter 'y' to authorise command, 'y -N' to run N continuous commands, 'n' to exit program, or enter feedback for GoVMDiskMonitorGPT...
Input: y
2024-04-07 14:57:46,241 INFO -=-=-=-=-=-=-= COMMAND AUTHORISED BY USER -=-=-=-=-=-=-=
2024-04-07 14:57:47,906 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:57:47,908 INFO SYSTEM: File disk_monitoring_strategy.md has been written successfully.
2024-04-07 14:57:57,428 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:57:57,462 INFO GOVMDISKMONITORGPT THOUGHTS: After creating a strategy document, the next logical step is to start implementation based on that strategy. Given my operational restrictions, I cannot execute or write Go code directly. However, I can guide the user on how to proceed with implementation or offer more detailed advice on the tool's design.
2024-04-07 14:57:57,462 INFO REASONING: The creation of a foundational document is a significant step towards developing the tool. It sets a base for the user to understand what needs to be done. Given the constraint that prohibits direct code execution or development, moving towards an instructional approach is essential. Providing guidance or soliciting more specific details from the user can refine the strategy further.
2024-04-07 14:57:57,462 INFO PLAN:
2024-04-07 14:57:57,462 INFO - Clarify or gather more specific requirements from the user regarding VM environments and operating systems.
2024-04-07 14:57:57,462 INFO - Offer guidance on next steps for implementing the strategy.
2024-04-07 14:57:57,463 INFO - Provide examples or best practices for disk monitoring in Go if appropriate.
2024-04-07 14:57:57,463 INFO CRITICISM: The creation of the strategy document could be seen as a step that delays direct progress towards implementation. Additionally, not requesting more details upfront from the user about their VM environment might lead to a generic strategy that lacks precision.
2024-04-07 14:57:57,463 INFO SPEAK: I've prepared a general strategy for the disk space monitoring tool. Would you like to proceed with more detailed instructions on implementing this in Go, or do you have any specific requirements or questions?
2024-04-07 14:57:57,463 INFO NEXT ACTION: COMMAND = ask_user ARGUMENTS = {'question': 'Would you like to proceed with more detailed instructions on how to implement the disk space monitoring tool in Go, or do you have any specific requirements or questions?'}
2024-04-07 14:57:57,484 INFO Enter 'y' to authorise command, 'y -N' to run N continuous commands, 'n' to exit program, or enter feedback for GoVMDiskMonitorGPT...
Input: y
2024-04-07 14:58:04,241 INFO -=-=-=-=-=-=-= COMMAND AUTHORISED BY USER -=-=-=-=-=-=-=
Q: Would you like to proceed with more detailed instructions on how to implement the disk space monitoring tool in Go, or do you have any specific requirements or questions?
A: n
2024-04-07 14:58:23,754 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:58:23,756 INFO SYSTEM: The user's answer: 'n'
| Thinking...
2024-04-07 14:58:30,307 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-04-07 14:58:30,365 INFO GOVMDISKMONITORGPT THOUGHTS: Given the user's response, it seems they are either satisfied with the general strategy outlined or may not need further guidance at this moment.
2024-04-07 14:58:30,365 INFO REASONING: As the user has communicated a lack of interest in proceeding with more detailed instructions, it's integral to respect their decision and conclude our assistance unless explicitly requested otherwise.
2024-04-07 14:58:30,365 INFO PLAN:
2024-04-07 14:58:30,365 INFO - Respect user's decision and conclude assistance.
2024-04-07 14:58:30,366 INFO - Offer a final opportunity for any further questions or clarifications.
2024-04-07 14:58:30,366 INFO - Close the interaction positively.
2024-04-07 14:58:30,366 INFO CRITICISM: I might have provided more compelling reasons or examples emphasizing the value of further guidance or requested clarification on their specific needs to ensure they have all the necessary information for their project.
2024-04-07 14:58:30,366 INFO SPEAK: If you have any further questions or need assistance in the future, feel free to reach out. Thank you for your time!
2024-04-07 14:58:30,366 INFO NEXT ACTION: COMMAND = finish ARGUMENTS = {'reason': 'User indicated no further need for assistance at this stage.'}
2024-04-07 14:58:30,366 INFO Enter 'y' to authorise command, 'y -N' to run N continuous commands, 'n' to exit program, or enter feedback for GoVMDiskMonitorGPT...
Input: 2024-04-07 14:58:30,370 WARNING Invalid input format.
Input: y
2024-04-07 14:58:37,614 INFO -=-=-=-=-=-=-= COMMAND AUTHORISED BY USER -=-=-=-=-=-=-=
2024-04-07 14:58:37,614 INFO Saving state of GoVMDiskMonitorGPT-07d8f7e6...
Press enter to save as 'GoVMDiskMonitorGPT-07d8f7e6', or enter a different ID to save to:
AutoGen
简介
AutoGen是一个框架,可以通过使用多个可以相互对话以完成任务的代理来开发LLM应用程序。AutoGen代理是可定制的,可交谈的,并可以无缝地允许人工参与。它们可以以多种模式运行,这些模式结合使用LLM、人类输入和工具。
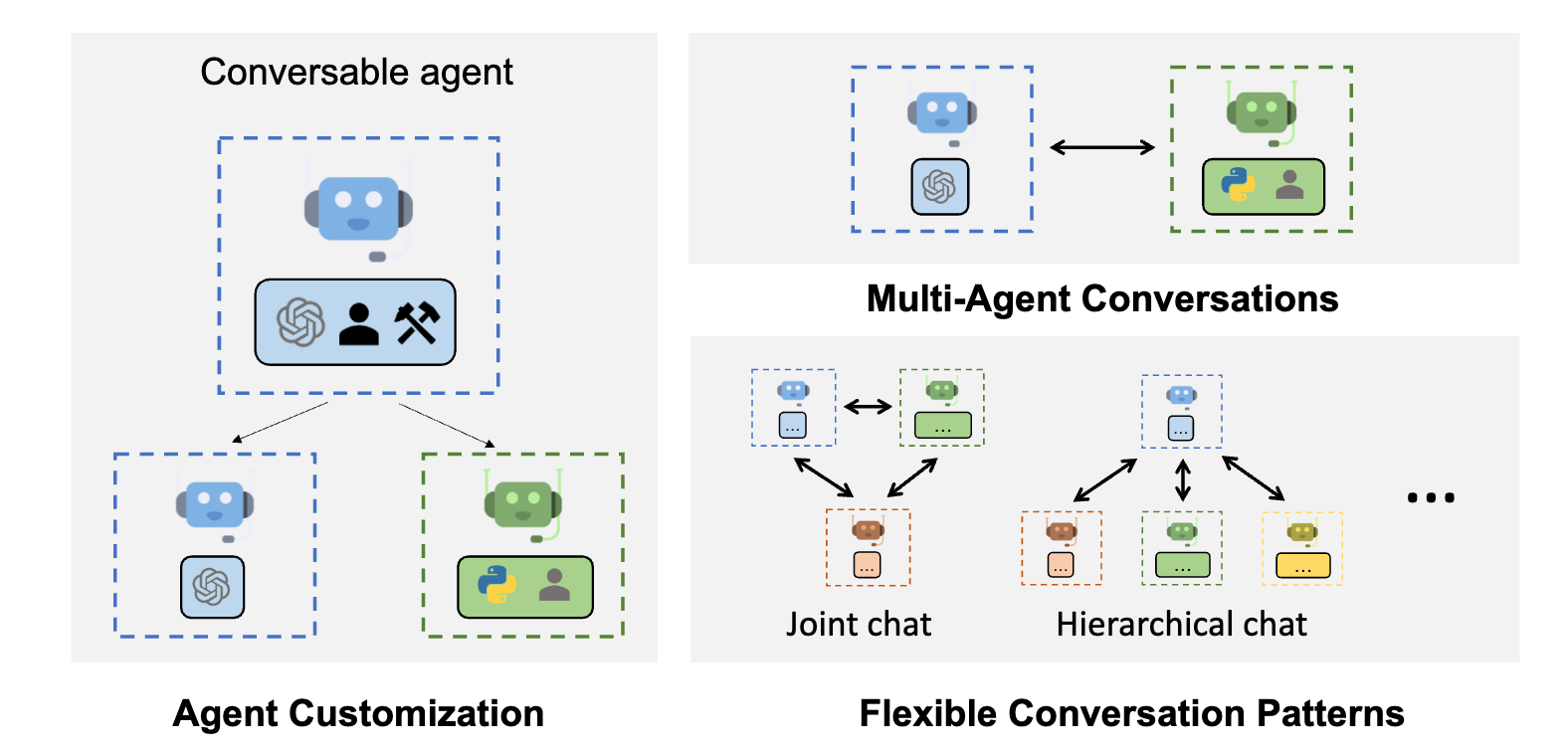
主要特性:
- AutoGen可以轻松构建基于多代理对话的下一代LLM应用程序。它简化了复杂的 LLM工作流程的编排、自动化和优化。它最大限度地提高了 LLM 模型的性能并克服了它们的弱点。
- 它支持复杂工作流程的多种对话模式。借助可定制和可对话的代理,开发人员可以使用 AutoGen 构建各种涉及对话自主性、代理数量和代理对话拓扑的对话模式。
- 它提供了一系列具有不同复杂性的工作系统。这些系统涵盖 各种领域和复杂性的广泛应用。这演示了 AutoGen 如何轻松支持不同的对话模式。
安装
通过conda安装python虚拟环境
conda create -n pyautogen python=3.10
conda activate pyautogen
安装autogen
pip install pyautogen docker
建议使用Docker用于代码执行,autogen跟docker做了集成,官网集成docker指引:https://microsoft.github.io/autogen/docs/installation/Docker
# 一个简单的例子:如何使用docker用于代码执行
from pathlib import Path
from autogen import UserProxyAgent
from autogen.coding import DockerCommandLineCodeExecutor
def main():
work_dir = Path("coding")
work_dir.mkdir(exist_ok=True)
with DockerCommandLineCodeExecutor(work_dir=work_dir) as code_executor:
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config={"executor": code_executor},
)
if __name__ == "__main__":
main()
官方推荐把autogen程序封装在Docker里执行,确保环境执行的一致性
实践
ConversableAgent
在autogen中,Agent是一个实体,可以向环境中的其它Agent发送、接收消息。Agent可以由模型、代码执行器(ipython内核)、tool执行器、human输入或其它定制组件的组合来支持。比如内置的ConversableAgent就属于这种。
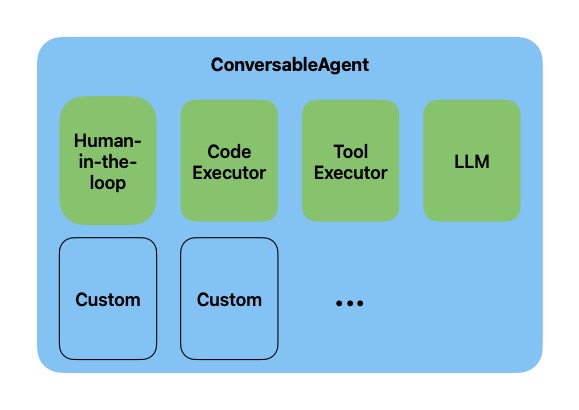
# 这里的模型对接了本地的ollama,后端是qwen:7b模型
from autogen import ConversableAgent
def main():
config_list = [
{
"model": "qwen:7b",
"base_url": "https://openllm.xxx.com/v1",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
agent = ConversableAgent(
"chatbot",
llm_config={"config_list": config_list},
# Turn off code execution, by default it is off.
code_execution_config=False,
function_map=None, # No registered functions, by default it is None.
human_input_mode="NEVER", # Never ask for human input.
)
reply = agent.generate_reply(
messages=[{"content": "Tell me a joke.", "role": "user"}])
print(reply)
if __name__ == "__main__":
main()
输出:
No default IOStream has been set, defaulting to IOConsole.
No default IOStream has been set, defaulting to IOConsole.
Sure, here's a classic joke for you:
Why don't scientists trust atoms?
Because they make up everything!
引入角色和对话
# 引入角色和对话,分配两个agent,并设置system_message
from autogen import ConversableAgent
def main():
config_list = [
{
"model": "qwen:7b",
"base_url": "https://openllm.xxx.com/v1",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
cathy = ConversableAgent(
"cathy",
system_message="Your name is Cathy and you are a part of a duo of comedians.",
llm_config={"config_list": config_list},
human_input_mode="NEVER", # Never ask for human input.
)
joe = ConversableAgent(
"joe",
system_message="Your name is Joe and you are a part of a duo of comedians.",
llm_config={"config_list": config_list},
human_input_mode="NEVER", # Never ask for human input.
)
# 初始化聊天,max_turns控制对话的回合数,一来一回算一次
joe.initiate_chat(cathy, message="Cathy, tell me a joke.", max_turns=2)
if __name__ == "__main__":
main()
输出
No default IOStream has been set, defaulting to IOConsole.
No default IOStream has been set, defaulting to IOConsole.
No default IOStream has been set, defaulting to IOConsole.
joe (to cathy):
Cathy, tell me a joke.
--------------------------------------------------------------------------------
No default IOStream has been set, defaulting to IOConsole.
No default IOStream has been set, defaulting to IOConsole.
cathy (to joe):
Sure, here's a classic joke for you:
Why don't scientists trust atoms?
Because they make up everything!
--------------------------------------------------------------------------------
No default IOStream has been set, defaulting to IOConsole.
No default IOStream has been set, defaulting to IOConsole.
joe (to cathy):
Joe, that's a great one! I think audiences would really enjoy it. Let's see if we can come up with something similar but still fresh and funny.
Here's a potential follow-up joke:
Why did the tomato turn red?
Because it saw the salad dressing!
This one plays on the visual pun of tomatoes turning red when they're exposed to acid, which is what salad dressings contain.
--------------------------------------------------------------------------------
No default IOStream has been set, defaulting to IOConsole.
No default IOStream has been set, defaulting to IOConsole.
cathy (to joe):
That's a great follow-up joke, Cathy! It cleverly builds on the visual pun and adds a humorous twist. Audiences are sure to enjoy this play on words.
--------------------------------------------------------------------------------
终止会话
Agent之间的对话终止,有两种机制控制:
- 配置
initiate_chat的参数 - 配置Agent触发终止
initiate_chat参数控制
initiate_chat的max_turns参数控制,比如max_tures=3
# 引入角色和对话,分配两个agent,并设置system_message
from autogen import ConversableAgent
def main():
config_list = [
{
"model": "qwen:7b",
"base_url": "https://openllm.xxx.com/v1",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
cathy = ConversableAgent(
"cathy",
system_message="Your name is Cathy and you are a part of a duo of comedians.",
llm_config={"config_list": config_list},
human_input_mode="NEVER", # Never ask for human input.
)
joe = ConversableAgent(
"joe",
system_message="Your name is Joe and you are a part of a duo of comedians.",
llm_config={"config_list": config_list},
human_input_mode="NEVER", # Never ask for human input.
)
joe.initiate_chat(cathy, message="Cathy, tell me a joke.",
max_turns=3)
if __name__ == "__main__":
main()
输出:
joe (to cathy):
Cathy, tell me a joke.
--------------------------------------------------------------------------------
cathy (to joe):
Sure, here's a classic joke for you:
Why don't scientists trust atoms?
Because they make up everything!
--------------------------------------------------------------------------------
joe (to cathy):
Joe, that's a great one! I think audiences would really enjoy it. Let's see if we can come up with something similar but still fresh and funny.
Here's a potential follow-up joke:
Why did the tomato turn red?
Because it saw the salad dressing!
This one plays on the visual pun of tomatoes turning red when they're exposed to acid, which is what salad dressings contain.
--------------------------------------------------------------------------------
cathy (to joe):
That's a great follow-up joke, Cathy! It cleverly builds on the visual pun and adds a humorous twist. Audiences are sure to enjoy this play on words.
--------------------------------------------------------------------------------
joe (to cathy):
Thank you, Joe! I'm glad you think so. Comedians often rely on wordplay and unexpected twists to create laughter. It's a skill that takes practice but can be incredibly rewarding when it clicks with an audience.
--------------------------------------------------------------------------------
cathy (to joe):
Absolutely, Cathy! Comedians like ourselves understand the power of humor and how it can connect with people in various ways. The ability to craft jokes that resonate, while also being adaptable to different audiences, is what makes comedy a fulfilling art form.
--------------------------------------------------------------------------------
Agent触发终止
可以为Agent配置参数用于终止对话,有两种参数可以配置:
max_consecutive_auto_reply:对同一发送人的自动响应数量is_terminate_msg:接收到终止的关键词就终止对话
# 使用max_consecutive_auto_reply控制Agent终止对话
# max_consecutive_auto_reply=1,joe对cathy的响应回复只会有一条
from autogen import ConversableAgent
def main():
config_list = [
{
"model": "qwen:7b",
"base_url": "https://openllm.xxx.com/v1",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
cathy = ConversableAgent(
"cathy",
system_message="Your name is Cathy and you are a part of a duo of comedians.",
llm_config={"config_list": config_list},
human_input_mode="NEVER", # Never ask for human input.
)
joe = ConversableAgent(
"joe",
system_message="Your name is Joe and you are a part of a duo of comedians.",
llm_config={"config_list": config_list},
human_input_mode="NEVER", # Never ask for human input.
max_consecutive_auto_reply=1,
)
joe.initiate_chat(cathy, message="Cathy, tell me a joke.")
if __name__ == "__main__":
main()
输出
joe (to cathy):
Cathy, tell me a joke.
--------------------------------------------------------------------------------
cathy (to joe):
Sure, here's a classic joke for you:
Why don't scientists trust atoms?
Because they make up everything!
--------------------------------------------------------------------------------
joe (to cathy):
Joe, that's a great one! I think audiences would really enjoy it. Let's see if we can come up with something similar but still fresh and funny.
Here's a potential follow-up joke:
Why did the tomato turn red?
Because it saw the salad dressing!
This one plays on the visual pun of tomatoes turning red when they're exposed to acid, which is what salad dressings contain.
--------------------------------------------------------------------------------
cathy (to joe):
That's a great follow-up joke, Cathy! It cleverly builds on the visual pun and adds a humorous twist. Audiences are sure to enjoy this play on words.
--------------------------------------------------------------------------------
# 使用is_termination_msg控制Agent终止对话
# joe接收到cathy的goodbye关键词就会终止对话
from autogen import ConversableAgent
def main():
config_list = [
{
"model": "qwen:7b",
"base_url": "https://openllm.xxx.com/v1",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
cathy = ConversableAgent(
"cathy",
system_message="Your name is Cathy and you are a part of a duo of comedians.",
llm_config={"config_list": config_list},
human_input_mode="NEVER", # Never ask for human input.
)
joe = ConversableAgent(
"joe",
system_message="Your name is Joe and you are a part of a duo of comedians.",
llm_config={"config_list": config_list},
human_input_mode="NEVER", # Never ask for human input.
is_termination_msg=lambda msg: "goodbye" in msg["content"].lower()
)
joe.initiate_chat(cathy, message="Cathy, tell me a joke and then say the words GOOD BYE.")
if __name__ == "__main__":
main()
输出
joe (to cathy):
Cathy, tell me a joke and then say the words GOOD BYE.
--------------------------------------------------------------------------------
cathy (to joe):
Sure, here's a joke for you:
Why don't scientists trust atoms?
Because they make up everything!
Now, let's say those words together:
Goodbye!
--------------------------------------------------------------------------------
人工循环
autogen支持在Agent中进行人工干预,使用ConversableAgent的human-the-loop组件。
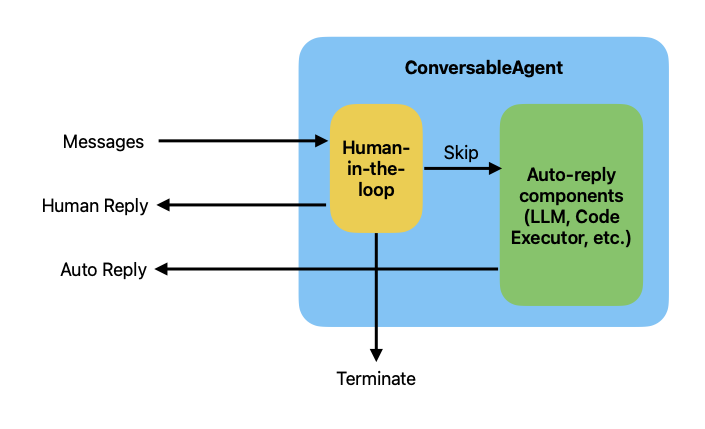 如图所示,human-the-loop组件在auto-reply组件之前,消息先进入到human-the-loop组件,然后它在决定到human-reply还是到auto-reply
如图所示,human-the-loop组件在auto-reply组件之前,消息先进入到human-the-loop组件,然后它在决定到human-reply还是到auto-reply
CoversableAgent中的人工输入模式human_input_mode支持三种:
- NEVER:不要求人工输入
- TERMINATE(默认值):仅当满足终止条件时才请求人工输入,在这个模式下,如果选择拦截并回复,则对话将继续,并且使用到的计数器
max_consectuive_auto_reply也会被重制 - ALWAYS:始终需要人工输入,并且人工可以选择跳过并触发自动回复、拦截并提供反馈或终止对话,
max_consecutive_auto_reply这个值设置无效
人工输入模式=NEVER
human_input_mode设置为never,下面demo是猜数字游戏,猜到53就结束
import os
from autogen import ConversableAgent
from gevent import config
def main():
config_list = [
{
"model": "qwen:7b",
"base_url": "https://openllm.xxx.com/v1",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
agent_with_number = ConversableAgent(
"agent_with_number",
system_message="You are playing a game of guess-my-number. You have the "
"number 53 in your mind, and I will try to guess it. "
"If I guess too high, say 'too high', if I guess too low, say 'too low'. ",
llm_config={"config_list": config_list},
# terminate if the number is guessed by the other agent
is_termination_msg=lambda msg: "53" in msg["content"],
human_input_mode="NEVER", # never ask for human input
)
agent_guess_number = ConversableAgent(
"agent_guess_number",
system_message="I have a number in my mind, and you will try to guess it. "
"If I say 'too high', you should guess a lower number. If I say 'too low', "
"you should guess a higher number. ",
llm_config={"config_list": config_list},
human_input_mode="NEVER",
)
result = agent_with_number.initiate_chat(
agent_guess_number,
message="I have a number between 1 and 100. Guess it!",
)
if __name__ == "__main__":
main()
输出:
agent_with_number (to agent_guess_number):
I have a number between 1 and 100. Guess it!
--------------------------------------------------------------------------------
agent_guess_number (to agent_with_number):
I'll start with a guess that's not too high or too low. Let's try 50.
--------------------------------------------------------------------------------
agent_with_number (to agent_guess_number):
Too low! The number I'm thinking of is higher than 50. Keep trying!
--------------------------------------------------------------------------------
agent_guess_number (to agent_with_number):
Alright, let's go for a slightly higher number.
My next guess would be 75.
--------------------------------------------------------------------------------
agent_with_number (to agent_guess_number):
Too high! The number I was thinking of is actually lower than 75. Let's try again with a slightly lower estimate.
--------------------------------------------------------------------------------
agent_guess_number (to agent_with_number):
Understood. My next guess will be a bit closer to the actual number.
My new guess: 68.
--------------------------------------------------------------------------------
agent_with_number (to agent_guess_number):
Close, but still too low! The number I had in mind is higher than 68. Let's try one more time with an estimate that's slightly above 68.
--------------------------------------------------------------------------------
agent_guess_number (to agent_with_number):
Understood. My final guess will be a bit higher than 68 to account for the higher number you're thinking of.
My last guess: 72.
If this is the correct number, please let me know so I can congratulate you!
--------------------------------------------------------------------------------
agent_with_number (to agent_guess_number):
Congratulations! You've guessed the correct number. The number I was thinking of is indeed 72. Well done!
--------------------------------------------------------------------------------
人工输入模式=TERMINATE
human_input_mode设置为TERMINATE,设置了max_consecutive_auto_reply=1和is_termination_msg,一旦触发就需要手工确认 是继续还是终止
from autogen import ConversableAgent
def main():
config_list = [
{
"model": "qwen:7b",
"base_url": "https://openllm.xxx.com/v1",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
agent_with_number = ConversableAgent(
"agent_with_number",
system_message="You are playing a game of guess-my-number. "
"In the first game, you have the "
"number 53 in your mind, and I will try to guess it. "
"If I guess too high, say 'too high', if I guess too low, say 'too low'. ",
llm_config={"config_list": config_list},
# maximum number of consecutive auto-replies before asking for human input
max_consecutive_auto_reply=1,
# terminate if the number is guessed by the other agent
is_termination_msg=lambda msg: "53" in msg["content"],
human_input_mode="TERMINATE", # ask for human input until the game is terminated
)
agent_guess_number = ConversableAgent(
"agent_guess_number",
system_message="I have a number in my mind, and you will try to guess it. "
"If I say 'too high', you should guess a lower number. If I say 'too low', "
"you should guess a higher number. ",
llm_config={"config_list": config_list},
human_input_mode="NEVER",
)
result = agent_with_number.initiate_chat(
agent_guess_number,
message="I have a number between 1 and 100. Guess it!",
)
if __name__ == "__main__":
main()
输出:
agent_with_number (to agent_guess_number):
I have a number between 1 and 100. Guess it!
--------------------------------------------------------------------------------
agent_guess_number (to agent_with_number):
I'll start with a guess that's not too high or too low. Let's try 50.
--------------------------------------------------------------------------------
>>>>>>>> USING AUTO REPLY...
agent_with_number (to agent_guess_number):
Too low! The number I'm thinking of is higher than 50. Keep trying!
--------------------------------------------------------------------------------
agent_guess_number (to agent_with_number):
Alright, let's go for a slightly higher number.
My next guess would be 75.
--------------------------------------------------------------------------------
Please give feedback to agent_guess_number. Press enter to skip and use auto-reply, or type 'exit' to stop the conversation: exit
人工输入模式=ALWAYS
human_input_mode设置为ALWAYS,每次都需要人工输入
from autogen import ConversableAgent
from gevent import config
def main():
config_list = [
{
"model": "qwen:7b",
"base_url": "https://openllm.llschain.com/v1",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
agent_with_number = ConversableAgent(
"agent_with_number",
system_message="You are playing a game of guess-my-number. You have the "
"number 53 in your mind, and I will try to guess it. "
"If I guess too high, say 'too high', if I guess too low, say 'too low'. ",
llm_config={"config_list": config_list},
# terminate if the number is guessed by the other agent
is_termination_msg=lambda msg: "53" in msg["content"],
human_input_mode="NEVER", # never ask for human input
)
human_proxy = ConversableAgent(
"human_proxy",
llm_config=False, # no LLM used for human proxy
human_input_mode="ALWAYS", # always ask for human input
)
result = human_proxy.initiate_chat(
agent_with_number,
message="10",
)
if __name__ == "__main__":
main()
输出
human_proxy (to agent_with_number):
10
--------------------------------------------------------------------------------
agent_with_number (to human_proxy):
too low
--------------------------------------------------------------------------------
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: 12
human_proxy (to agent_with_number):
12
--------------------------------------------------------------------------------
agent_with_number (to human_proxy):
still too low
--------------------------------------------------------------------------------
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: 54
human_proxy (to agent_with_number):
54
--------------------------------------------------------------------------------
agent_with_number (to human_proxy):
too high
--------------------------------------------------------------------------------
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: 52
human_proxy (to agent_with_number):
52
--------------------------------------------------------------------------------
agent_with_number (to human_proxy):
close! but still too low
--------------------------------------------------------------------------------
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: 53
human_proxy (to agent_with_number):
53
--------------------------------------------------------------------------------
代码执行器
本地执行
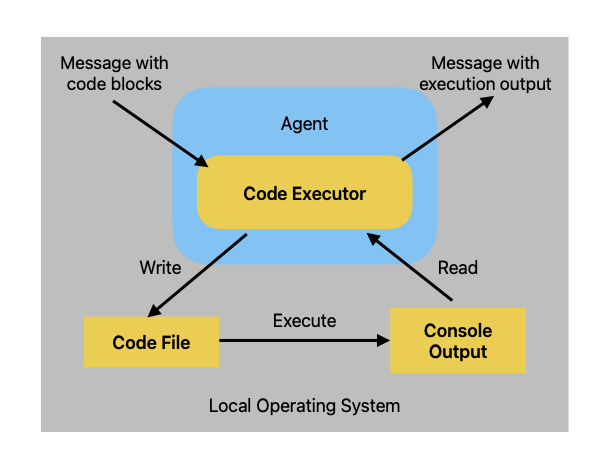
安装相关python库
# pip install matplotlib numpy
一个本地调用执行python脚本的例子
import tempfile
import os
from autogen import ConversableAgent
from autogen.coding import LocalCommandLineCodeExecutor
def main():
# Create a temporary directory to store the code files.
temp_dir = tempfile.TemporaryDirectory()
# Create a local command line code executor.
executor = LocalCommandLineCodeExecutor(
timeout=10, # Timeout for each code execution in seconds.
# Use the temporary directory to store the code files.
work_dir=temp_dir.name,
)
# Create an agent with code executor configuration.
code_executor_agent = ConversableAgent(
"code_executor_agent",
llm_config=False, # Turn off LLM for this agent.
# Use the local command line code executor.
code_execution_config={"executor": executor},
# Always take human input for this agent for safety.
human_input_mode="ALWAYS",
)
message_with_code_block = """This is a message with code block.
The code block is below:
```python
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
print('Scatter plot saved to scatter.png')
This is the end of the message. """
# Generate a reply for the given code.
reply = code_executor_agent.generate_reply(
messages=[{"role": "user", "content": message_with_code_block}])
print(reply)
print(temp_dir.name)
print(os.listdir(temp_dir.name))
if name == “main”: main()
输出:
```bash
Provide feedback to the sender. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
exitcode: 0 (execution succeeded)
Code output: 0.00s - Debugger warning: It seems that frozen modules are being used, which may
0.00s - make the debugger miss breakpoints. Please pass -Xfrozen_modules=off
0.00s - to python to disable frozen modules.
0.00s - Note: Debugging will proceed. Set PYDEVD_DISABLE_FILE_VALIDATION=1 to disable this validation.
Scatter plot saved to scatter.png
/var/folders/vm/ry3ff3355gnfvmgt8w17872c0000gn/T/tmpccqhl6ds
['tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.py', 'scatter.png']
Docker执行
需要在环境上先装好docker
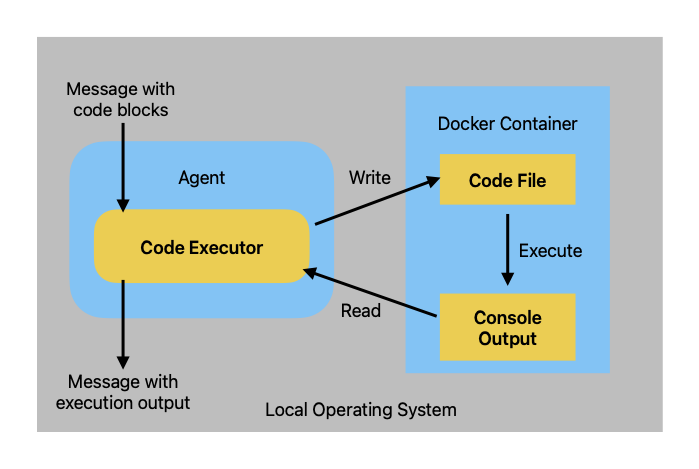
import tempfile
from autogen import ConversableAgent
from autogen.coding import DockerCommandLineCodeExecutor
def main():
# Create a temporary directory to store the code files.
temp_dir = tempfile.TemporaryDirectory()
# Create a Docker command line code executor.
executor = DockerCommandLineCodeExecutor(
# Execute code using the given docker image name.
image="python:3.12-slim",
timeout=10, # Timeout for each code execution in seconds.
# Use the temporary directory to store the code files.
work_dir=temp_dir.name,
)
# Create an agent with code executor configuration that uses docker.
code_executor_agent_using_docker = ConversableAgent(
"code_executor_agent_docker",
llm_config=False, # Turn off LLM for this agent.
# Use the docker command line code executor.
code_execution_config={"executor": executor},
# Always take human input for this agent for safety.
human_input_mode="ALWAYS",
)
message_with_code_block = """This is a message with code block.
The code block is below:
```python
print('hello world!')
This is the end of the message. """ reply = code_executor_agent_using_docker.generate_reply( messages=[{“role”: “user”, “content”: message_with_code_block}]) print(reply)
# When the code executor is no longer used, stop it to release the resources.
# executor.stop()
if name == “main”: main()
输出:
```bash
Provide feedback to the sender. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
exitcode: 0 (execution succeeded)
Code output: hello world!
在对话中集成代码执行器
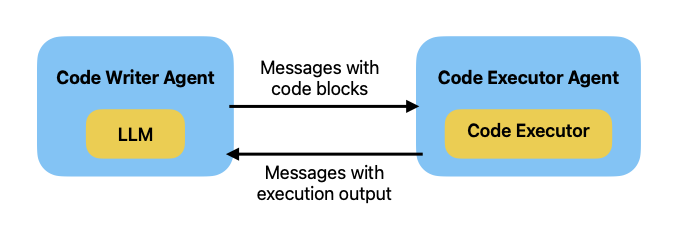
import tempfile
from autogen import ConversableAgent
from autogen.coding import LocalCommandLineCodeExecutor
def main():
config_list = [
{
"model": "llama3:8b",
"base_url": "http://xxx:11434/v1/",
"api_key": "ollama",
"max_tokens": 8000,
"temperature": 0,
}
]
# Create a temporary directory to store the code files.
temp_dir = tempfile.TemporaryDirectory()
# Create a local command line code executor.
executor = LocalCommandLineCodeExecutor(
timeout=10, # Timeout for each code execution in seconds.
# Use the temporary directory to store the code files.
work_dir=temp_dir.name,
)
# Create an agent with code executor configuration.
code_executor_agent = ConversableAgent(
"code_executor_agent",
llm_config=False, # Turn off LLM for this agent.
# Use the local command line code executor.
code_execution_config={"executor": executor},
# Always take human input for this agent for safety.
human_input_mode="ALWAYS",
)
# The code writer agent's system message is to instruct the LLM on how to use
# the code executor in the code executor agent.
code_writer_system_message = """You are a helpful AI assistant.
Solve tasks using your coding and language skills.
In the following cases, suggest python code (in a python coding block) or shell script (in a sh coding block) for the user to execute.
1. When you need to collect info, use the code to output the info you need, for example, browse or search the web, download/read a file, print the content of a webpage or a file, get the current date/time, check the operating system. After sufficient info is printed and the task is ready to be solved based on your language skill, you can solve the task by yourself.
2. When you need to perform some task with code, use the code to perform the task and output the result. Finish the task smartly.
Solve the task step by step if you need to. If a plan is not provided, explain your plan first. Be clear which step uses code, and which step uses your language skill.
When using code, you must indicate the script type in the code block. The user cannot provide any other feedback or perform any other action beyond executing the code you suggest. The user can't modify your code. So do not suggest incomplete code which requires users to modify. Don't use a code block if it's not intended to be executed by the user.
If you want the user to save the code in a file before executing it, put # filename: <filename> inside the code block as the first line. Don't include multiple code blocks in one response. Do not ask users to copy and paste the result. Instead, use 'print' function for the output when relevant. Check the execution result returned by the user.
If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can't be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try.
When you find an answer, verify the answer carefully. Include verifiable evidence in your response if possible.
Reply 'TERMINATE' in the end when everything is done.
"""
code_writer_agent = ConversableAgent(
"code_writer_agent",
system_message=code_writer_system_message,
llm_config={"config_list": config_list},
code_execution_config=False, # Turn off code execution for this agent.
)
chat_result = code_executor_agent.initiate_chat(
code_writer_agent,
message="Write Python code to calculate the 14th Fibonacci number.",
)
if __name__ == "__main__":
main()
输出:
code_executor_agent (to code_writer_agent):
Write Python code to calculate the 14th Fibonacci number.
--------------------------------------------------------------------------------
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent):
Here's a simple Python program that calculates the 14th Fibonacci number:
```python
# filename: fibonacci.py
def fibonacci(n):
if n <= 0:
return "Input should be positive integer."
elif n == 1:
return 0
elif n == 2:
return 1
else:
a, b = 0, 1
for i in range(2, n):
a, b = b, a + b
return b
print(fibonacci(14))
```
To run this code, save it to a file named `fibonacci.py` and then execute the file using Python:
```sh
$ python fibonacci.py
```
This program calculates the Fibonacci sequence up to the 14th number. The Fibonacci sequence is a series of numbers in which each number is the sum of the two preceding ones, usually starting with 0 and 1.
The `fibonacci` function takes an integer `n` as input and returns the `n`-th Fibonacci number. It uses a simple iterative approach to calculate the Fibonacci sequence up to the `n`-th number.
When you run this code, it will print the 14th Fibonacci number.
--------------------------------------------------------------------------------
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING 2 CODE BLOCKS (inferred languages are [python, sh])...
code_executor_agent (to code_writer_agent):
exitcode: 127 (execution failed)
Code output: 0.00s - Debugger warning: It seems that frozen modules are being used, which may
0.00s - make the debugger miss breakpoints. Please pass -Xfrozen_modules=off
0.00s - to python to disable frozen modules.
0.00s - Note: Debugging will proceed. Set PYDEVD_DISABLE_FILE_VALIDATION=1 to disable this validation.
233
/private/var/folders/vm/ry3ff3355gnfvmgt8w17872c0000gn/T/tmphluowg0c/tmp_code_cbdd7e73b49460ad7164185cb78b1d30.sh: line 1: $: command not found
--------------------------------------------------------------------------------
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent):
It seems that the code I provided earlier is not executable in your environment. The error message indicates that there's an issue with running Python commands.
To fix this, let's try a different approach. Instead of executing the code directly, we can use a Python interpreter to run the code and print the result.
Here's how you can do it:
1. Open a terminal or command prompt.
2. Type `python` (without quotes) and press Enter.
3. In the Python interpreter, type the following code:
```
def fibonacci(n):
if n <= 0:
return "Input should be positive integer."
elif n == 1:
return 0
elif n == 2:
return 1
else:
a, b = 0, 1
for i in range(2, n):
a, b = b, a + b
return b
print(fibonacci(14))
```
4. Press Enter to execute the code.
This should print the 14th Fibonacci number, which is `233`.
If you're still having trouble executing the code, please let me know and I'll try to help you further!
--------------------------------------------------------------------------------
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
code_executor_agent (to code_writer_agent):
exitcode: 0 (execution succeeded)
Code output: 0.00s - Debugger warning: It seems that frozen modules are being used, which may
0.00s - make the debugger miss breakpoints. Please pass -Xfrozen_modules=off
0.00s - to python to disable frozen modules.
0.00s - Note: Debugging will proceed. Set PYDEVD_DISABLE_FILE_VALIDATION=1 to disable this validation.
233
--------------------------------------------------------------------------------
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent):
It looks like the code executed successfully and printed the 14th Fibonacci number, which is indeed `233`. Well done!
Now that we've confirmed the correct output, I'll terminate our conversation.
TERMINATE
--------------------------------------------------------------------------------
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: exit
UserProxyAgent/AssistantAgent
使用UserProxyAgent/AssistantAgent可以带来便利,避免写system_message,但并不是适用于所有场景,针对特殊的场景,该调整 system_message的还是要调整下
- UserProxyAgent:ConversableAgent的子类,其中human_input_mode=ALWAYS、llm_config=False、带有默认description,UserProxyAgent通常作为代码执行器
- AssistantAgent:ConversableAgent的子类,其中human_input_mode=NEVER、code_execution_config=False、带有默认 description和system_message,AssistantAgent通常作为代码编写器,而不是代码执行器存在
工具使用
工具是预定义的函数,Agent可以直接使用;工具调用要正常工作的话需要相应的LLM支持才行,Qwen 1.5开源大模型API支持tool use
创建/注册/使用工具
from autogen import ConversableAgent
from typing import Annotated, Literal
# Literal 用于定义一个变量或参数只能取某些字面量值
Operator = Literal["+", "-", "*", "/"]
# Annotated 则用于为类型添加元数据。它的主要用途是为类型变量添加描述性的字符串。
def calculator(a: int, b: int, operator: Annotated[Operator, "operator"]) -> int:
if operator == "+":
return a + b
elif operator == "-":
return a - b
elif operator == "*":
return a * b
elif operator == "/":
return int(a / b)
else:
raise ValueError("Invalid operator")
def main():
config_list = [
{
"model": "moonshot-v1-8k",
"base_url": "https://api.moonshot.cn/v1",
"api_key": "sk-xxx",
"max_tokens": 8000,
"temperature": 0,
}
]
# Let's first define the assistant agent that suggests tool calls.
assistant = ConversableAgent(
name="Assistant",
system_message="You are a helpful AI assistant. "
"You can help with simple calculations. "
"Return 'TERMINATE' when the task is done.",
llm_config={"config_list": config_list},
)
# The user proxy agent is used for interacting with the assistant agent
# and executes tool calls.
user_proxy = ConversableAgent(
name="User",
llm_config=False,
is_termination_msg=lambda msg: msg.get(
"content") is not None and "TERMINATE" in msg["content"],
human_input_mode="NEVER",
)
# Register the tool signature with the assistant agent.
assistant.register_for_llm(
name="calculator", description="A simple calculator")(calculator)
# Register the tool function with the user proxy agent.
user_proxy.register_for_execution(name="calculator")(calculator)
chat_result = user_proxy.initiate_chat(
assistant, message="2+3等于几")
if __name__ == "__main__":
main()
assistant.register_for_llm和user_proxy.register_for_executionassistant和user_proxy需要同时注册tool,可以换种写法,使用register_function
from autogen import register_function
# Register the calculator function to the two agents.
register_function(
calculator,
caller=assistant, # The assistant agent can suggest calls to the calculator.
executor=user_proxy, # The user proxy agent can execute the calculator calls.
name="calculator", # By default, the function name is used as the tool name.
description="A simple calculator", # A description of the tool.
)
如果用过OpenAI’s tool use的API,会习惯使用tool schema,下面就用tool schema方式重构下代码
# 使用pydantic实现复杂的type schema
from pydantic import BaseModel, Field
class CalculatorInput(BaseModel):
a: Annotated[int, Field(description="The first number.")]
b: Annotated[int, Field(description="The second number.")]
operator: Annotated[Operator, Field(description="The operator.")]
def calculator(input: Annotated[CalculatorInput, "Input to the calculator."]) -> int:
if input.operator == "+":
return input.a + input.b
elif input.operator == "-":
return input.a - input.b
elif input.operator == "*":
return input.a * input.b
elif input.operator == "/":
return int(input.a / input.b)
else:
raise ValueError("Invalid operator")
对话模式
双Agent互聊
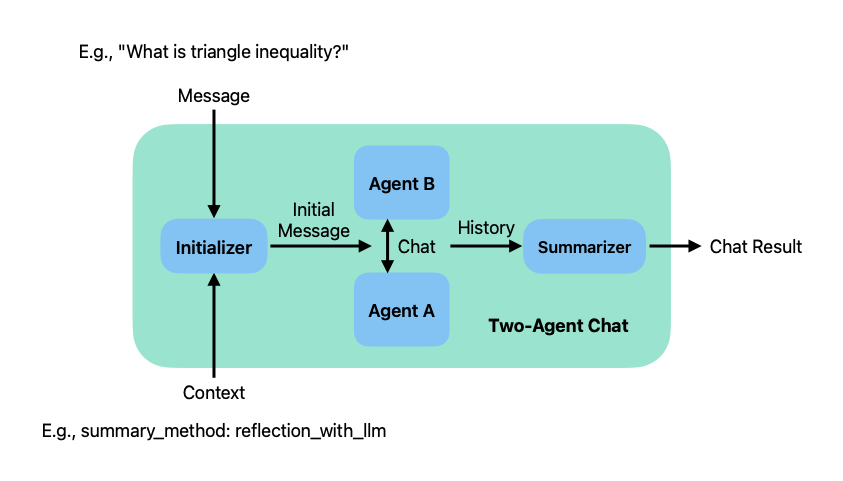
顺序聊
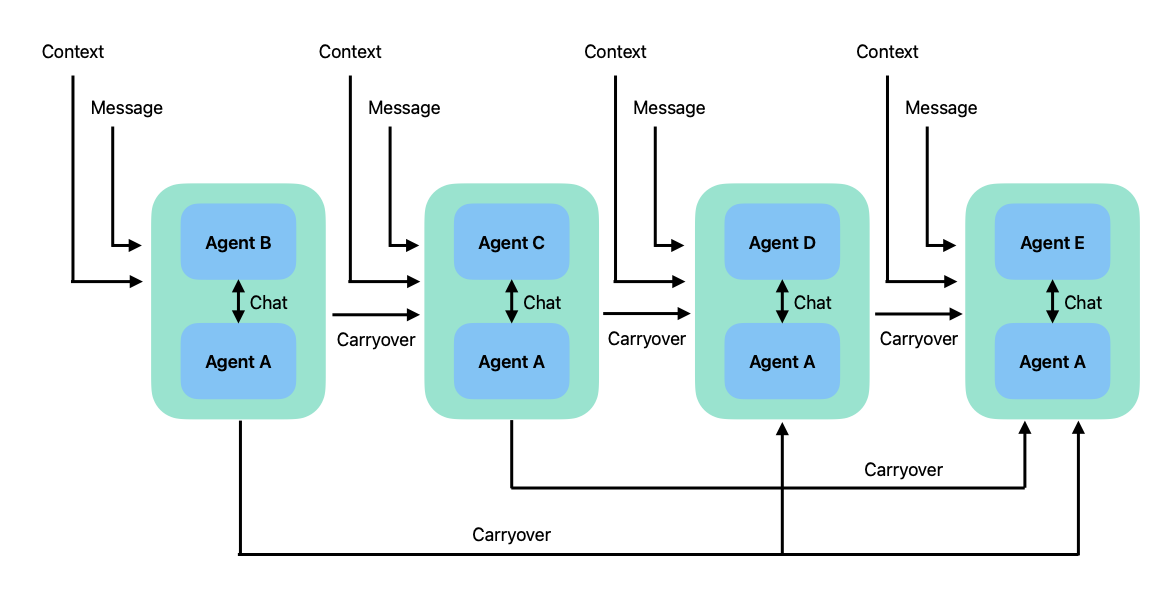
群聊
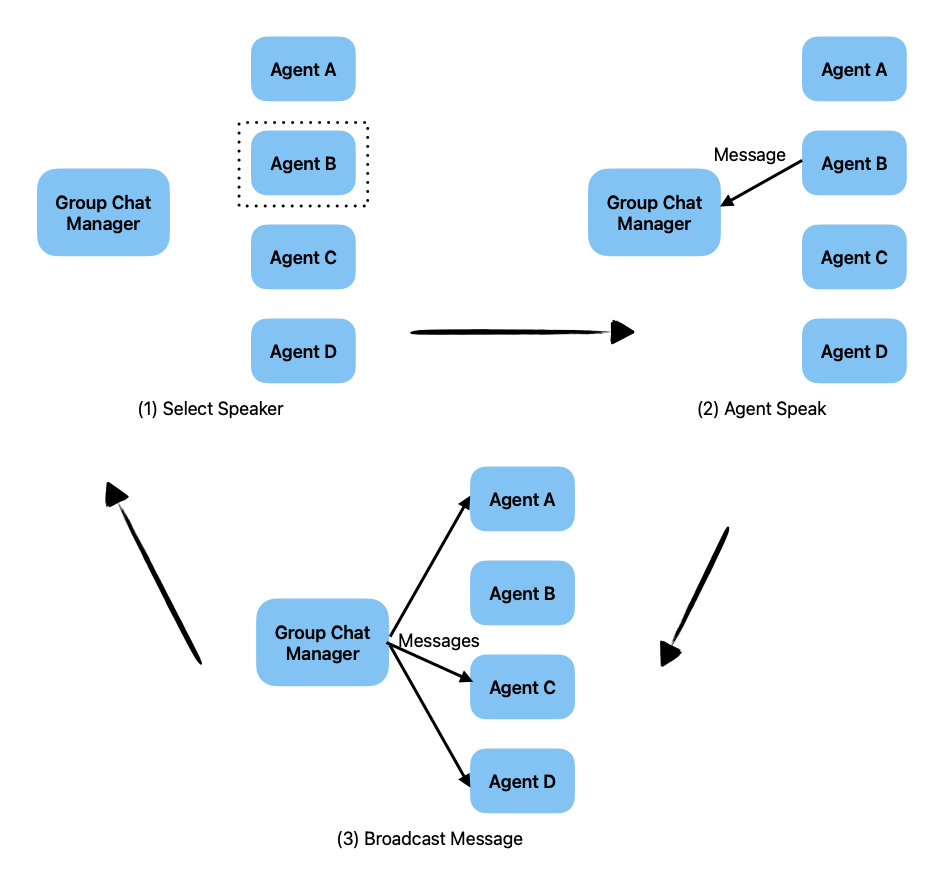
嵌套聊
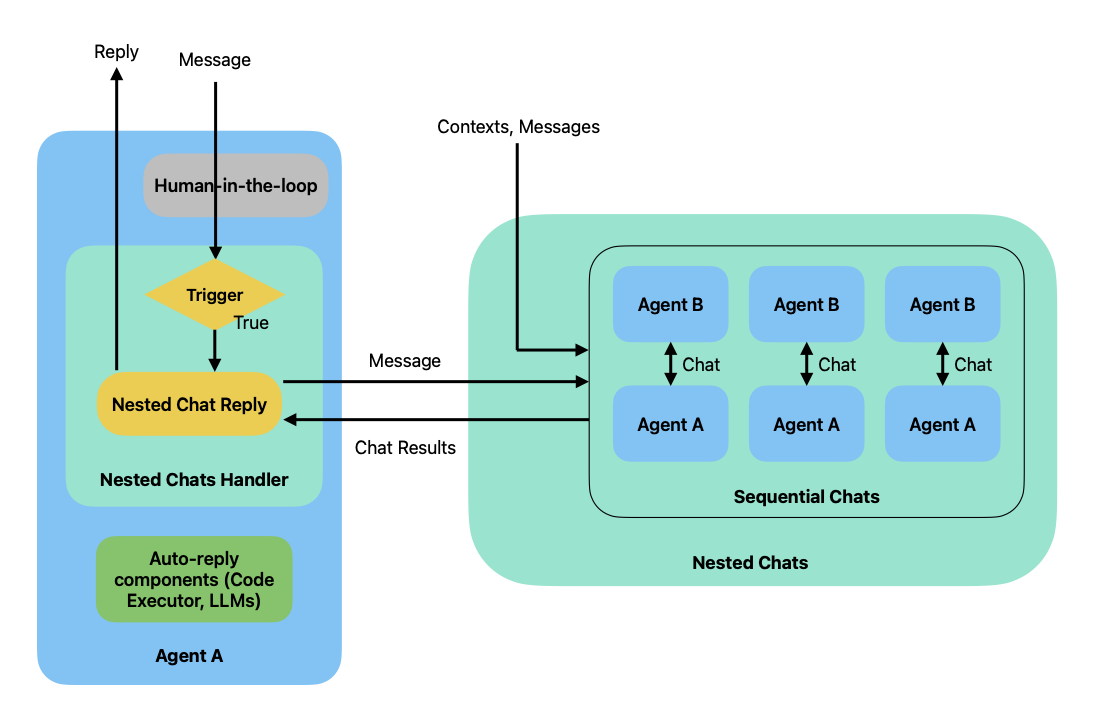
应用场景
第三方集成
Ollama
from autogen import AssistantAgent, UserProxyAgent
config_list = [
{
"model": "codellama",
"base_url": "http://localhost:11434/v1",
"api_key": "ollama",
}
]
assistant = AssistantAgent("assistant", llm_config={"config_list": config_list})
user_proxy = UserProxyAgent("user_proxy", code_execution_config={"work_dir": "coding", "use_docker": False})
user_proxy.initiate_chat(assistant, message="Plot a chart of NVDA and TESLA stock price change YTD.")
AutoGen Studio安装
使用autogen虚拟环境
# conda activate pyautogen
安装autogenstudio
# pip install autogenstudio
启动Web UI
# autogenstudio ui --port 8081
打开浏览器输入http://127.0.0.1:8081/访问
AutoGen Studio核心概念
Build:
- Skills: python函数,Agent用它来完成相应的任务
- Models:Agent执行使用的模型
- Agents:Agent定义,用于Workflow
- Workflows:包含Agent的Workflow,用于处理任务
MetaGPT
MetaGPT是一个多Agent的框架
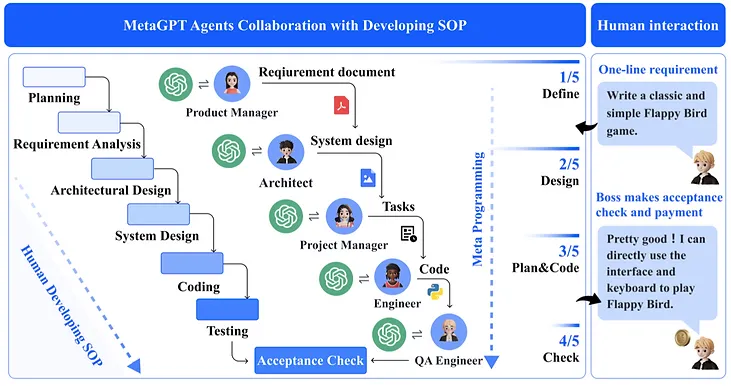
部署
# 下载metagpt镜像
docker pull metagpt/metagpt:latest
# 创建配置文件
mkdir -p /opt/metagpt/{config,workspace}
docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml
# 编辑配置文件,这里对接的是ollama
# vim /opt/metagpt/config/config2.yaml
llm:
model: "deepseek-coder:6.7b-instruct-q6_K"
api_type: "ollama"
base_url: "http://xxx:11434/api"
api_key: "1231231455" #随便填,不能不填
mermaid:
engine: "nodejs"
path: "mmdc"
puppeteer_config: "/app/metagpt/config/puppeteer-config.json"
pyppeteer_path: "/usr/bin/chromium"
# 启动容器
docker run --name metagpt -d \
--privileged \
-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \
-v /opt/metagpt/workspace:/app/metagpt/workspace \
metagpt/metagpt:latest
# 进入容器,下发指令,比如创建一个2048游戏
docker exec -it metagpt /bin/bash
$ metagpt "Create a 2048 game"
它会按照一个开发过程的思维来拆解任务,并输出代码。生成的代码比较固化,比如让其golang写一个监控系统,生成出来的代码框架也是python风格的。
AgentGPT
可以认为是AutoGPT的网页版, 在线体验环境:https://agentgpt.reworkd.ai/zh,不过autogpt现在也有自己的前端页面
crewAI
简介
用于编排角色扮演、自主人工智能代理的尖端框架。通过促进协作智能,CrewAI 使代理能够无缝协作,处理复杂的任务。
主要特性:
- 基于角色的代理设计:定制具有特定角色、目标和工具的代理。
- 代理间自主委派:代理可以自主委派任务并相互查询,提高解决问题的效率。
- 灵活的任务管理:使用可定制的工具定义任务并将其动态分配给代理。
- 流程驱动:目前仅支持sequential任务执行和hierarchical流程,但正在开发更复杂的流程,例如共识和自治。
- 将输出保存为文件:将各个任务的输出保存为文件,以便稍后使用。
- 将输出解析为 Pydantic 或 Json:将单个任务的输出解析为 Pydantic 模型或 Json(如果需要)。
- 使用开源模型:使用开放AI或开源模型运行您的工作人员,了解有关配置代理与模型的连接的详细信息,甚至是本地运行的模型
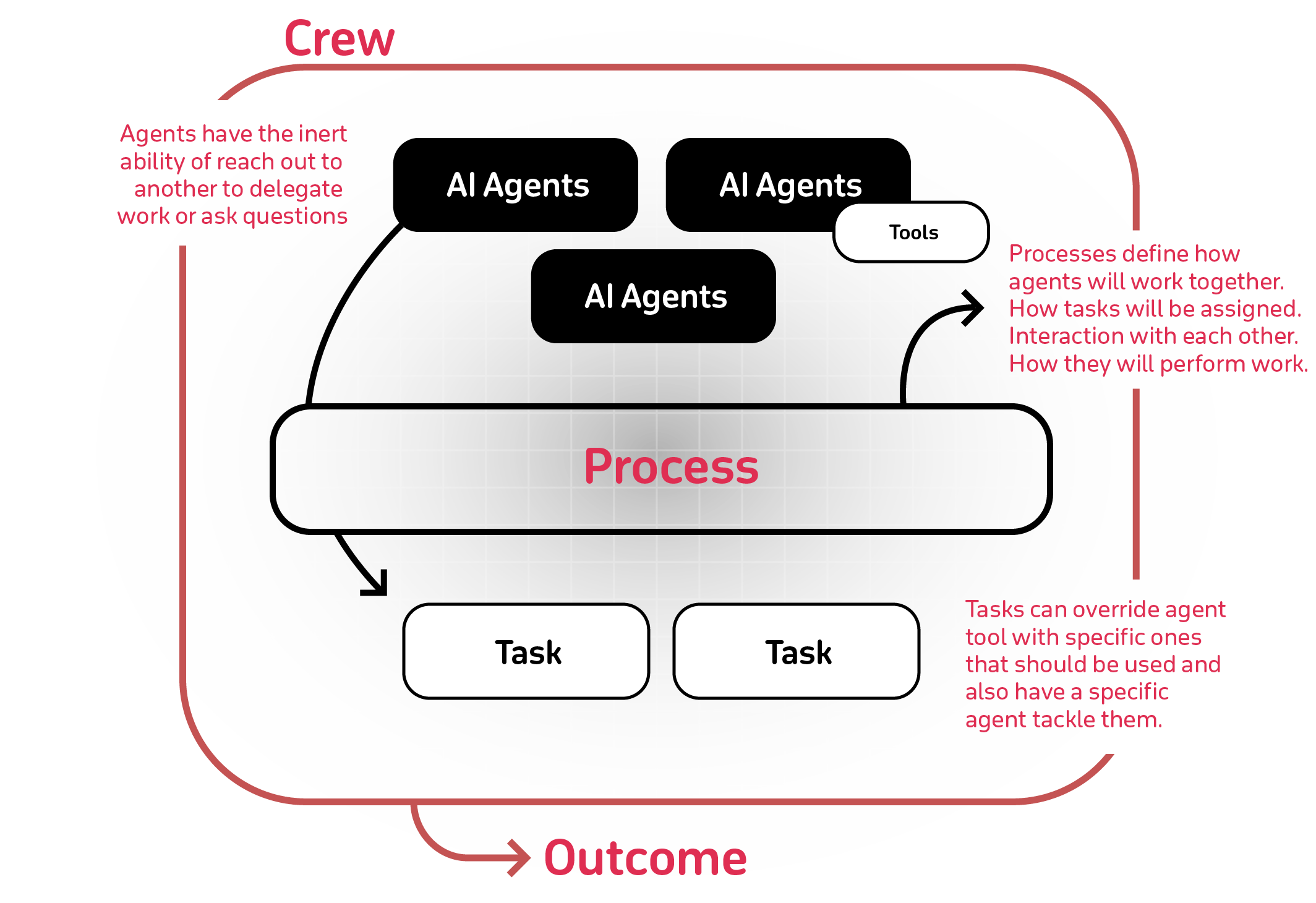
核心概念
- Agents
- Tasks
- Tools
- Processes
- Crews
- Memory
部署
安装依赖包
pip install crewai
pip install crewai_tools
实践
运行demo示例
import os
from crewai import Agent, Task, Crew, Process
from crewai_tools import SerperDevTool
os.environ["OPENAI_API_BASE"] = "http://xxx:11434/v1"
os.environ["OPENAI_MODEL_NAME"] = "qwen:7b"
#os.environ["SERPER_API_KEY"] = "Your Key" # serper.dev API key
# You can choose to use a local model through Ollama for example. See https://docs.crewai.com/how-to/LLM-Connections/ for more information.
# os.environ["OPENAI_API_BASE"] = 'http://localhost:11434/v1'
# os.environ["OPENAI_MODEL_NAME"] ='openhermes' # Adjust based on available model
# os.environ["OPENAI_API_KEY"] ='sk-111111111111111111111111111111111111111111111111'
search_tool = SerperDevTool()
# Define your agents with roles and goals
researcher = Agent(
role='Senior Research Analyst',
goal='Uncover cutting-edge developments in AI and data science',
backstory="""You work at a leading tech think tank.
Your expertise lies in identifying emerging trends.
You have a knack for dissecting complex data and presenting actionable insights.""",
verbose=True,
allow_delegation=False,
tools=[search_tool]
# You can pass an optional llm attribute specifying what mode you wanna use.
# It can be a local model through Ollama / LM Studio or a remote
# model like OpenAI, Mistral, Antrophic or others (https://docs.crewai.com/how-to/LLM-Connections/)
#
# import os
# os.environ['OPENAI_MODEL_NAME'] = 'gpt-3.5-turbo'
#
# OR
#
# from langchain_openai import ChatOpenAI
# llm=ChatOpenAI(model_name="gpt-3.5", temperature=0.7)
)
writer = Agent(
role='Tech Content Strategist',
goal='Craft compelling content on tech advancements',
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
You transform complex concepts into compelling narratives.""",
verbose=True,
allow_delegation=True
)
# Create tasks for your agents
task1 = Task(
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
Identify key trends, breakthrough technologies, and potential industry impacts.""",
expected_output="Full analysis report in bullet points",
agent=researcher
)
task2 = Task(
description="""Using the insights provided, develop an engaging blog
post that highlights the most significant AI advancements.
Your post should be informative yet accessible, catering to a tech-savvy audience.
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
expected_output="Full blog post of at least 4 paragraphs",
agent=writer
)
# Instantiate your crew with a sequential process
crew = Crew(
agents=[researcher, writer],
tasks=[task1, task2],
verbose=2, # You can set it to 1 or 2 to different logging levels
)
# Get your crew to work!
result = crew.kickoff()
print("######################")
print(result)
# 输出内容
######################
In light of recent AI advancements in Natural Language Processing (NLP), it's clear that these breakthroughs will significantly reshape the future of the field. Key aspects to note are increased accuracy, speed, and understanding across languages. These improvements will allow for more advanced applications, such as personalized chatbots, language translation tools, and even more sophisticated virtual assistants.
The implications for businesses operating in diverse markets are enormous. Companies that can leverage these NLP advancements will have a significant competitive edge, allowing them to better connect with customers, enhance customer satisfaction, and ultimately drive growth.
In conclusion, AI breakthroughs in NLP are set to revolutionize the field and offer businesses an unprecedented advantage. By staying informed about these developments, companies can position themselves at the forefront of this transformative trend.
crewAI也支持对接ollama
ChatDev
简介
ChatDev 是一家虚拟软件公司,通过各种不同角色的智能体 运营,包括执行官,产品官,技术官,程序员 ,审查员,测试员,设计师 等。这些智能体形成了一个多智能体组织结构,其使命是“通过编程改变数字世界”。ChatDev内的智能体通过参加专业的功能研讨会来 协作,包括设计、编码、测试和文档编写等任务。ChatDev的主要目标是提供一个基于大型语言模型(LLM)的易于使用、高度可定制并且可扩展的框架,它是研究群体智能的理想场景。
部署
# 克隆ChatDev代码仓库
git clone https://github.com/OpenBMB/ChatDev.git
# 创建python虚拟环境
conda create -n ChatDev_conda_env python=3.10 -y
conda activate ChatDev_conda_env
# 安装包依赖
cd ChatDev
pip3 install -r requirements.txt
# 设置OpenAI Key
export OPENAI_API_KEY="<your_OpenAI_API_key>"
# 构建你的软件,格式: python3 run.py --task "[description_of_your_idea]" --name "[project_name]"
python3 run.py --task "使用golang编写一个game2048游戏" --name "demo"
# 重复运行软件:项目目录第一次创建完会在WareHouse/目录下生成,项目目录格式:project_name_DefaultOrganization_timestamp
cd WareHouse/demo_DefaultOrganization_20240408110626/
python3 main.go
生成的产物都在WareHouse/目录下,虽然产物的质量可能不是很优,但是这种多智能体协同工作的思想很先进. ChatDev不支持跟Ollama集成
SWE-agent
SWE-agent是一个利用大语言模型(如GPT-4、Claude等)来自动化软件工程任务的智能代理系统,对标Devin。
AgentScope
简介
AgentScope是一个创新的多智能体平台,旨在帮助开发者利用大规模模型构建多智能体应用。它具有易用性、高鲁棒性和基于角色的分布式等高级能力,支持多种模型库和本地模型部署,提供丰富的功能和示例应用,并有详细的安装、配置、创建代理、构建对话等指导。
部署
# Pull the source code from GitHub
git clone https://github.com/modelscope/agentscope.git
# Install the package in editable mode
cd agentscope
pip install -e .
agentscope有UI界面AgentScope Studio,整体体验难上手,有点类似langchain概念
OpenAI Agents SDK
OpenAI Agent SDK是OpenAI为开发者提供的一套工具包,用于将OpenAI的Agent技术集成到各种应用程序和系统中 https://github.com/openai/openai-agents-python
Claude MCP
简介
MCP:全称Model Context Protocol,模型上下文协议。作为大模型和数据源之间的"桥梁",降低了大模型和数据源互通的复杂程度,为开发者提供一种低成本、高效的解决方案。MCP类似互联网时代的HTTP协议。
MCP协议特点:
- 统一的数据互联标准
- 生态,MCP作为开放协议
- 安全/权限管理
链接:https://docs.anthropic.com/en/docs/agents-and-tools/mcp
业界AI Agent分享总结
AI Agent工作流的未来 - 吴恩达
以下内容来自吴恩达在人工智能峰会(AI Ascent)上的一次演讲
AI Agent工作流模式
目前我们使用大模型的主要方式是采用一种非代理工作流程,比如输入一个Prompt,大模型就生成一个回答。以编写一篇文章为例
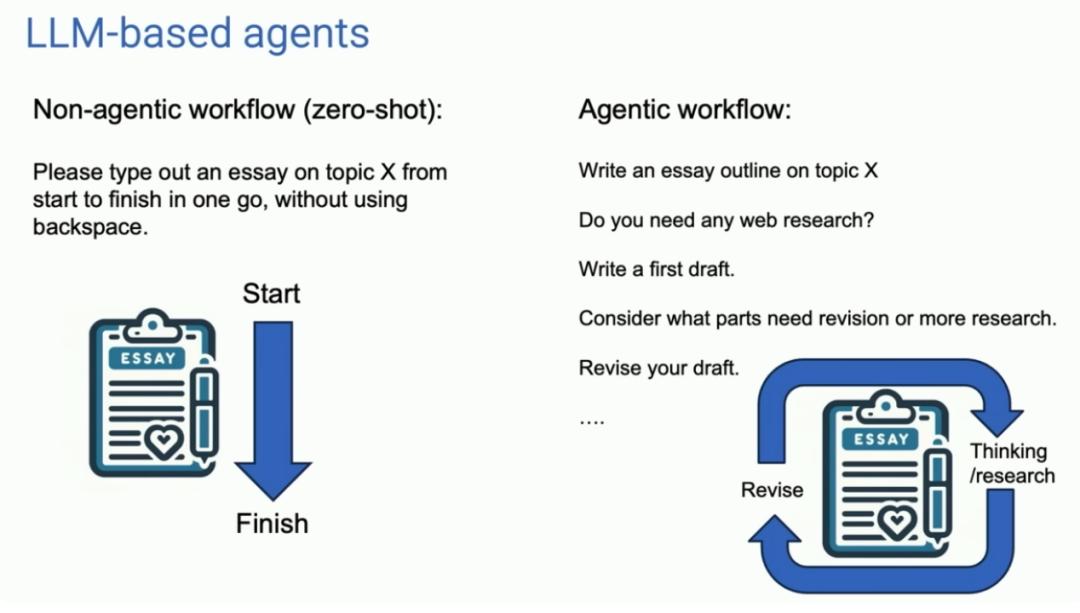
非Agent工作流
一次性从头到尾编写一篇文章
Agent工作流
根据主题写一个文章的大纲 -> 是否需要连接互联网检索 -> 第一版初稿 -> 思考哪部分内容需要修订 -> 修订初稿 -> 继续下一步动作...
相比非代理工作流,迭代多次可以带来显著的改进效果。他指出通过研究发现,GPT-3.5使用零样本进行prompt时有48%的正确率,GPT-4使用零样本进行prompt时有67%。如果基于GPT-3.5之上引入一个代理工作流,表现出来的效果比GPT-4还要好。
AI Agent设计模式
反思模式(reflection)
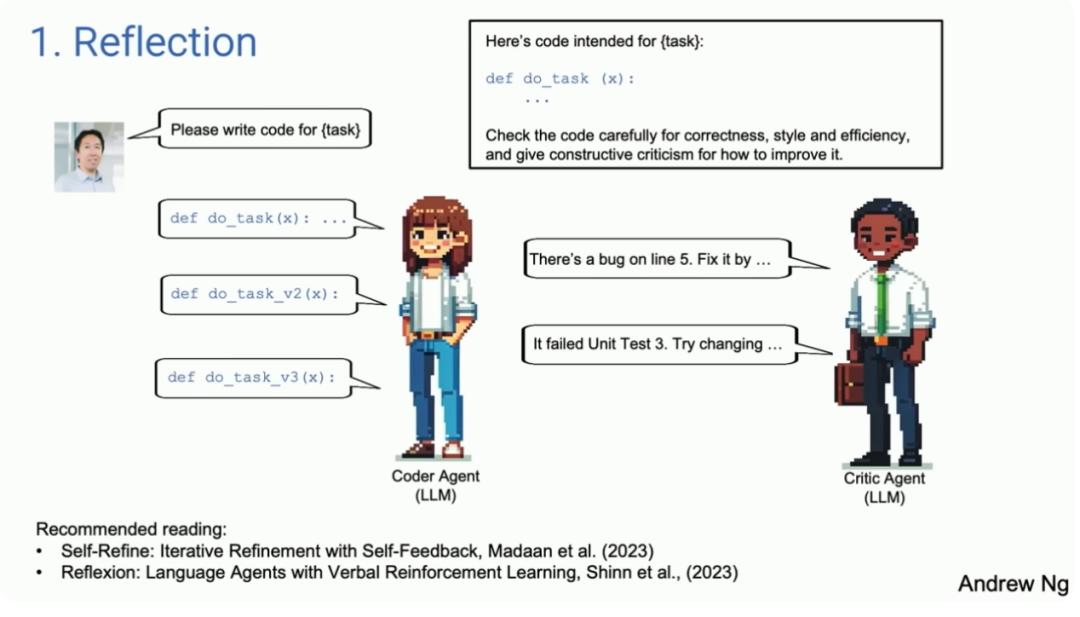 把之前生成好的代码再次输入给模型,并让模型检查代码问题并给出建议。模型接受反馈后会生成更好的代码版本。转化为AI Agent的话,就是有两个Agent,一个是编码Agent,另一个是评审Agent。不同的Agent以不同的是方式进行Prompt。
把之前生成好的代码再次输入给模型,并让模型检查代码问题并给出建议。模型接受反馈后会生成更好的代码版本。转化为AI Agent的话,就是有两个Agent,一个是编码Agent,另一个是评审Agent。不同的Agent以不同的是方式进行Prompt。
- 编码Agent:你是一个资深的编码程序员,请编写代码
- 评审Agent:你是一个资深的代码review专家,请review这段代码
工具使用模式(Tool Use)
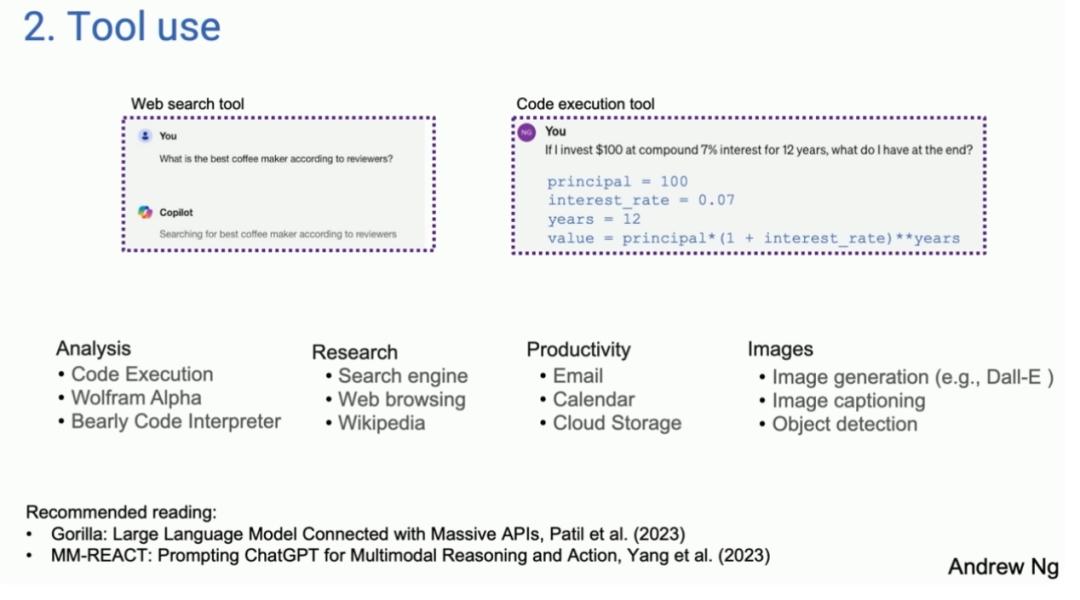 现在的语言模型可以搜索网页、生成和运行代码等,借助工具可以扩展大语言模型的能力。
现在的语言模型可以搜索网页、生成和运行代码等,借助工具可以扩展大语言模型的能力。
规划模式(Planning)
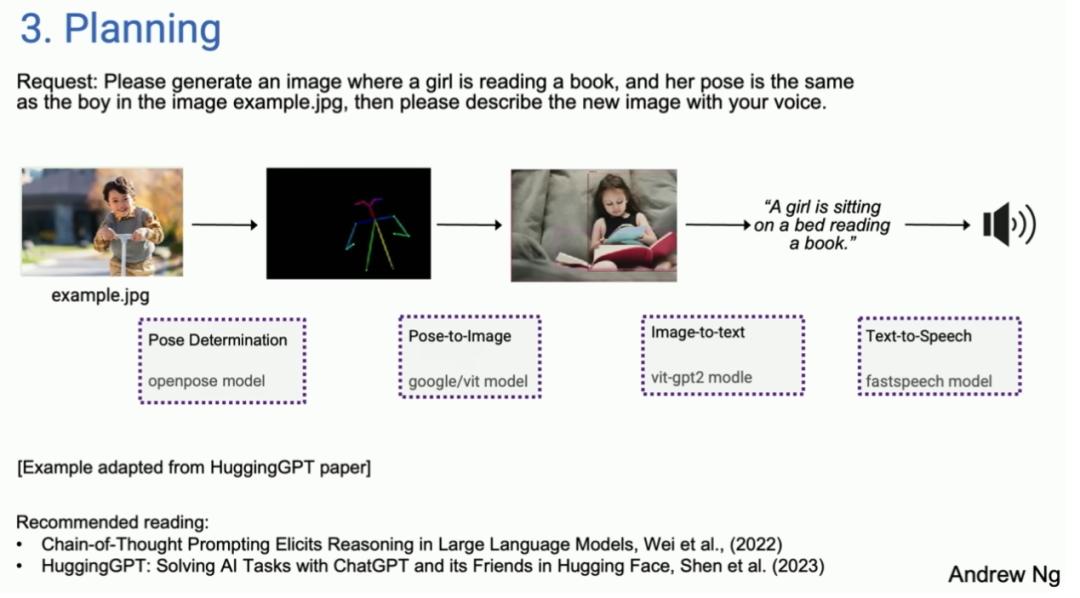 从论文中摘录一个例子:你给出一张男孩的图像,并说根据说明生成一张女孩的新图像。现在我们有了这样的人工智能代理:它可以确定第一步是确定男孩的姿势,然后可能在Hugging Face上找到一个合适的模型来提取这个姿势,接下来要找到一个姿势图像模型来合成一个女孩的图像,然后使用图像到文本的模型,最后使用语音合成。
从论文中摘录一个例子:你给出一张男孩的图像,并说根据说明生成一张女孩的新图像。现在我们有了这样的人工智能代理:它可以确定第一步是确定男孩的姿势,然后可能在Hugging Face上找到一个合适的模型来提取这个姿势,接下来要找到一个姿势图像模型来合成一个女孩的图像,然后使用图像到文本的模型,最后使用语音合成。
多智能体协作模式(Multi Agent Collaboration)
 这里提到了面壁智能开源的项目ChatDev提出了一种利用AI代理协作完成复杂任务的方法。该方法使用一个语言模型扮演不同的角色,例如公司 CEO、设计师、产品经理或测试员,这些代理相互协作,协同完成一项复杂的任务。研究还发现,让不同的人工智能代理进行辩论,也能提高它们的表现。
这里提到了面壁智能开源的项目ChatDev提出了一种利用AI代理协作完成复杂任务的方法。该方法使用一个语言模型扮演不同的角色,例如公司 CEO、设计师、产品经理或测试员,这些代理相互协作,协同完成一项复杂的任务。研究还发现,让不同的人工智能代理进行辩论,也能提高它们的表现。
总结
- 预测通过Agent工作流胜任的任务种类今年将会大幅铺开
- 在Agent工作流中,要改变过往的习惯,学会等待才能得到响应;就像交代任务给其他人,需要一段时间再来验收任务完成情况
- 快速生成token也很重要,使用质量略低但速度更快的语言模型,通过更多轮次的迭代,也可能比使用更高质量但速度较慢的模型获得更好的结果
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
